MapR just released Python and Java support for their MapR-DB connector for Spark. It also supports Scala, but Python and Java are new. I recorded a video to help them promote it, but I also learned a lot in the process, relating to how databases can be used in Spark.
If you want to use a database to persist a Spark dataframe (or RDD, or Dataset), you need a piece of software the connects that databse to Spark. Here is a list of database that can be connected to Spark. Without getting into the relative strengths of one database over another, there are a couple of capabilities you should look for when you’re picking a database to use with Spark. These are characteristics of the database’s Spark connector, not of the database:
- Filter and Projection Pushdown. I.e. When you select columns and use the SQL
whereclause to select rows in a table, those operations get executed on the database. All other SQL operators, likeorder byorgroup byare computed in the Spark executor. - Automatic Schema Inference
- Support for RDDs, Dataframes, and Datasets
- Bulk save
There are also those intangible nice-to-haves, like language support (python/java/scala), IDE support (intellij/netbeans/eclipse), and notebook support (jupyter/zeppelin).
Here is a video demo that I recorded which talks about the MapR-DB connector for Spark:

I also wrote a Jupyter notebook to demonstrate the MapR-DB connector for Spark, which is shown below:
Jupyter Notebook
MapR-DB OJAI Connector for Apache Spark¶
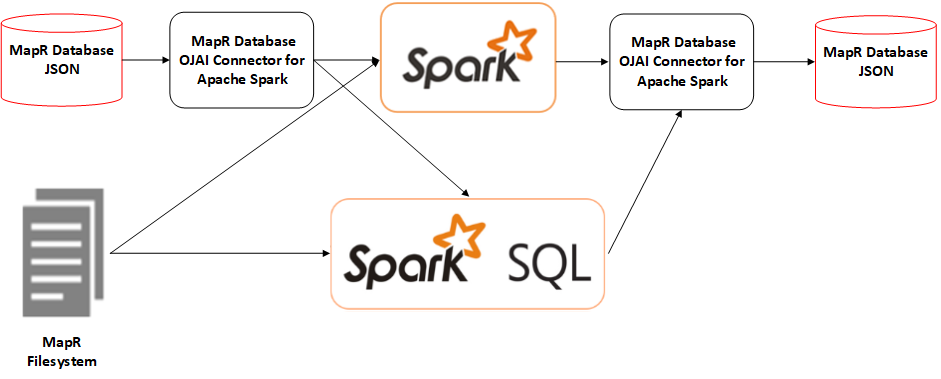
This notebook shows how to perform CRUD operations on MapR-DB JSON tables using the Spark Python API (PySpark). The connector that makes this possible is called MapR-DB OJAI Connector for Apache Spark. For more information about this connector see https://maprdocs.mapr.com/home/Spark/NativeSparkConnectorJSON.html. <img src = https://maprdocs.mapr.com/home/Spark/images/OJAIConnectorForSpark.png width=50%>
Prerequisites:¶
- MapR: 6.0 or later
- MEP 4.1 or later
- Spark 2.1.0 or later
- Scala 2.11 or later
- Java 8 or later
from pyspark.sql.functions import monotonically_increasing_id
from pyspark.sql.types import *
from pyspark.sql import Row
import pandas as pd
import numpy as np
import os
import matplotlib
import matplotlib.pyplot as plt
get_ipython().run_line_magic('matplotlib', 'inline')
import random
import shutil
# First create a SparkSession object.
spark = SparkSession.builder.appName("OJAI_examples").getOrCreate()
Write to MapR-DB¶
# Saving a DataFrame
d = [{'_id':'1', 'name': 'Alice', 'age': 1}]
df = spark.createDataFrame(d)
spark.saveToMapRDB(df, "/tmp/people")
# create_table is false by default
try:
spark.saveToMapRDB(df, "/tmp/people", create_table=True)
except:
# TableExistsException will occur if the table has already been created
spark.saveToMapRDB(df, "/tmp/people", create_table=False)
# Index must not be null.
df = spark.createDataFrame([("Bilbo Baggins", 50), ("Gandalf", 1000), ("Thorin", 195), ("Bombur", None)], ["name", "age"])
spark.saveToMapRDB(df, "/tmp/people", id_field_path='name')
df.show()
# Index is the '_id' column by default.
# If index is sorted, use bulk_insert=True to insert faster.
df = df.withColumn("_id", monotonically_increasing_id().cast("string"))
spark.saveToMapRDB(df, "/tmp/people", bulk_insert=True)
df.show()
# Saving a DataFrame with a manually defined schema
schema = StructType([StructField('_id', StringType()), StructField('name', StringType()), StructField('age',IntegerType())])
rows = [Row(_id='1', name='Severin', age=33), Row(_id='2', name='John', age=48)]
df = spark.createDataFrame(rows, schema)
df.printSchema()
df.show()
spark.saveToMapRDB(df, "/tmp/people")
saveToMapRDB options¶
spark.saveToMapRDB(df, "/tmp/people", id_field_path='_id', create_table=False, bulk_insert=False
Read from MapR-DB¶
# Load a MapR-DB table into a DataFrame.
# The table path is in the MapR-XD filesystem namespace
df = spark.loadFromMapRDB("/apps/business")
df.count()
# createOrReplaceTempView creates a lazily evaluated "view" that you can use with Spark SQL.
# It does not persist to memory unless you cache the dataset that underpins the view.
df.createOrReplaceTempView("table1")
# SQL statements can be run by using the sql methods provided by sqlContext.
df2 = spark.sql("SELECT _id, state, stars from table1")
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
# plot a histogram of the data
plt.hist(x=df2.select('stars').toPandas(), normed=1, rwidth=.25)
plt.xlabel('Stars')
plt.ylabel('Probability')
plt.grid(True)
plt.show()

# Get a list of all the businesses with ratings less than 1.5 stars
df3 = df2[df2['Stars'] < 1.5]
# same thing:
# df3 = df2.filter(df2.stars < 1.5)
print(df3.count())
# Save our subset of businesses to a new table using MapR-DB OJAI connector
try:
spark.saveToMapRDB(df3, "/apps/bad_business", create_table=True)
except:
# TableExistsException will occur if the table has already been created
spark.saveToMapRDB(df3, "/apps/bad_business", create_table=False)
Automatic Schema Discovery¶
# Schema will be automatically inferred when you load a table
df = spark.loadFromMapRDB("/apps/people")
print(df.count())
df.printSchema()
# You can manually specify the schema if you want.
# Note: MapR-DB JSON understands Date data types
random.seed(111)
daterange = pd.date_range(start='2018-01-29', periods=1000)
data = {'_id': np.arange(0,len(daterange)),
'timestamp': daterange,
'x': np.random.uniform(-10, 10, size=len(daterange))}
df = pd.DataFrame(data, columns = ['_id', 'timestamp', 'x'])
print(type(df))
df.head(2)
d = [{'_id':'1', 'date': '1970-01-01', 'x': 1}]
df = spark.createDataFrame(d)
spark.saveToMapRDB(df, "/tmp/timeseries", create_table=True)
schema = StructType([StructField('_id', StringType()),
StructField('date', StringType()),
StructField('x',FloatType())])
df = spark.loadFromMapRDB("/tmp/timeseries")
print(df.count())
df.printSchema()
df.take(1)
schema = StructType([StructField('_id', StringType()),
StructField('date', DateType()),
StructField('x',LongType())])
df = spark.loadFromMapRDB("/tmp/timeseries", schema=schema)
print(df.count())
df.printSchema()
print(df.take(1))
Filter Push-Down and Database Projection¶
- Aggregation clauses like
whereandorder bywill be pushed down and executed by MapR-DB. - MapR-DB processes data in-place, without ETL.
- The Spark executor only sees the fields (columns) which were requested and rows selected. This is called "projection".
# Aggregation clauses like 'where' and 'order by' will be pushed down and executed by MapR-DB.
# The results of SQL queries are DataFrames and support all the normal RDD operations.
df3 = sqlContext.sql("SELECT _id, state, stars FROM table1 WHERE stars >= 3 order by state")
# The columns of a row in the result can be accessed by field index:
df3.map(t => "Name: " + t(0)).collect().foreach(println)
# or by field name.
df3.map(t => "Name: " + t.getAs[String]("name")).collect().foreach(println)
# row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T]
df3.map(_.getValuesMap[Any](List("name", "age"))).collect().foreach(println)
Please provide your feedback to this article by adding a comment to https://github.com/iandow/iandow.github.io/issues/8.

{kind=link}