“MapR-DB is the perfect database for Customer 360 applications”. That’s the tag line I used to describe a demo I created for MapR for the Strata Data Conference in New York in September of 2017. Describing Customer 360 as a use case for MapR-DB was the focus of this demo because we wanted to draw attention to the new features being unveiled for MapR-DB. I really like the Customer 360 use case because it talks to so many of MapR’s strengths (not just DB) and it can be told in a story that is both visually appealing and technically deep.
Frequently the needs of marketing and product management are at odds because marketeers want to capture leads with flashy demos but product managers want to show off technical features that may not show well but appeal to the discriminating tastes of brainiac developers. At times it was hard to reconcile these opposing viewpoints while building the Customer 360 demo but with the help of the bokeh data visualization framework and the MapR’s database connector for Spark I was able to achieve demonstrable elegance in both the front-end and the back-end.
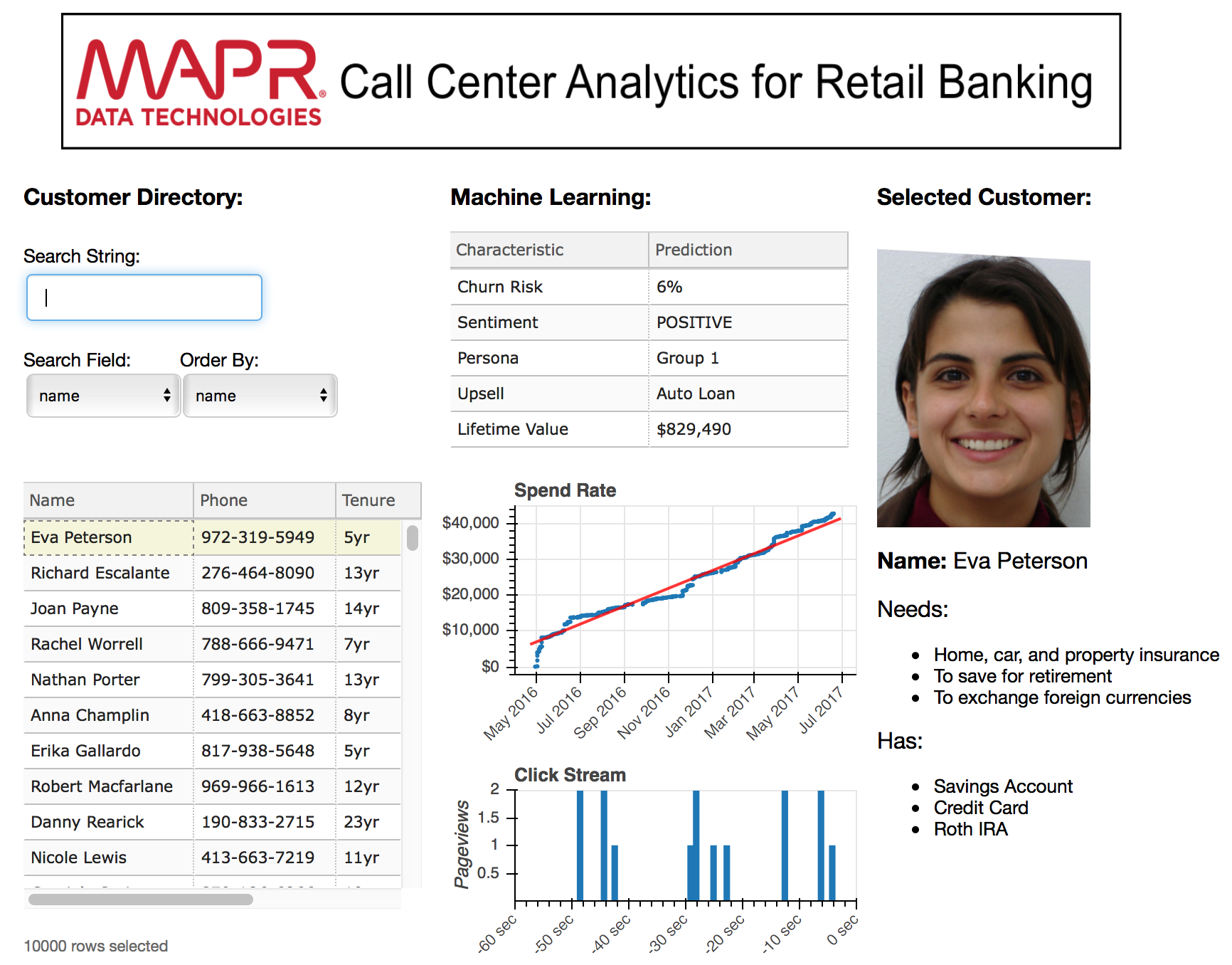
Product demos as booth provocations need to be flashy. My efforts to build flashiness in the front-end were rewarded more than once when an attendee asked if they could take a photo of my app (insert a mental fist pump here) but my back-end code was an equally elegant Spark process that loaded RDDs using connectors to Kafka and MapR-DB, then joined those RDDs to perform churn predictions and saved that machine learning insight back into MapR-DB where it could be immediately accessible by production apps. The streaming data contained user clicks flowing through a MapR Streams topic. The MapR-DB tables contained properties for customers. Here’s what that data flow looked like:
Demo Objectives
The three key points I’m trying to convey with this demo are:
- Flexible schemas makes it easier to persist Customer 360 data.
- Operating streams and database services on one cluster makes it easier to analyze that data in Spark.
- Operating database services and machine learning on one cluster makes it easier for production applications to access machine learning results.
Customer 360 databases must support flexible schemas.
MapR-DB is the perfect database for Customer 360 because it allows you to store data for customers with different properties in the same table (and because it’s scalable, reliable, resiliant, etc …but I want to focus on it’s ability to handle flexible schemas for customer data). Why does that matter? Well, for customer 360 you’re trying to integrate as many datasets as possible. For example you might be trying to ingest all the data your customers expose publicly on social media, or you might be trying to ingest data they expose through your mobile app, but not all customers may use social media and not all customer may use your mobile app. Nevertheless, a NoSQL database like MapR-DB can store data for all customers in one table even if different columns are used for each customer. The sparsity in columnar data is not a problem at all for MapR-DB.
Converging streams and database eliminates data movement.
MapR’s platform provides both distributed streaming and distributed database so we can load real-time data (like click streams) and table data (like CRM data) into Spark without moving data. That’s really important because anytime you move data, especially Big Data, the analysis of that data becomes much slower. In the world of Big Data, data movement is BAD!
Production applications get smarter when they share a common database with Spark.
The third major talking point relates to how we can take an output, like churn prediction, from machine learning processes and load it back into master CRM tables so those insights become instantly accessible by production applications. A lot of companies do analytics on integrated datasets, which you can call Customer 360, but they fail to operationalize those insights by saving them back into their master customer data tables. When ML processes and production apps share a common master database, its much easier to operationalize ML insights.
Using Zeppelin for Customer 360
To illustrate my demo objectives in code, I wrote a Zeppelin notebook which runs the following tasks in Spark:
- Read clickstream data from MapR Streams using Spark Streaming and the Kafka API
- Output performance data for web traffic using Spark SQL
- Combine clickstream data with master CRM data using the Spark connector to MapR-DB
- Predict churn from feature columns in the combined clickstream / CRM data and save churn predictions back into MapR-DB tables.
I’ve posted my Zeppelin notebook here.
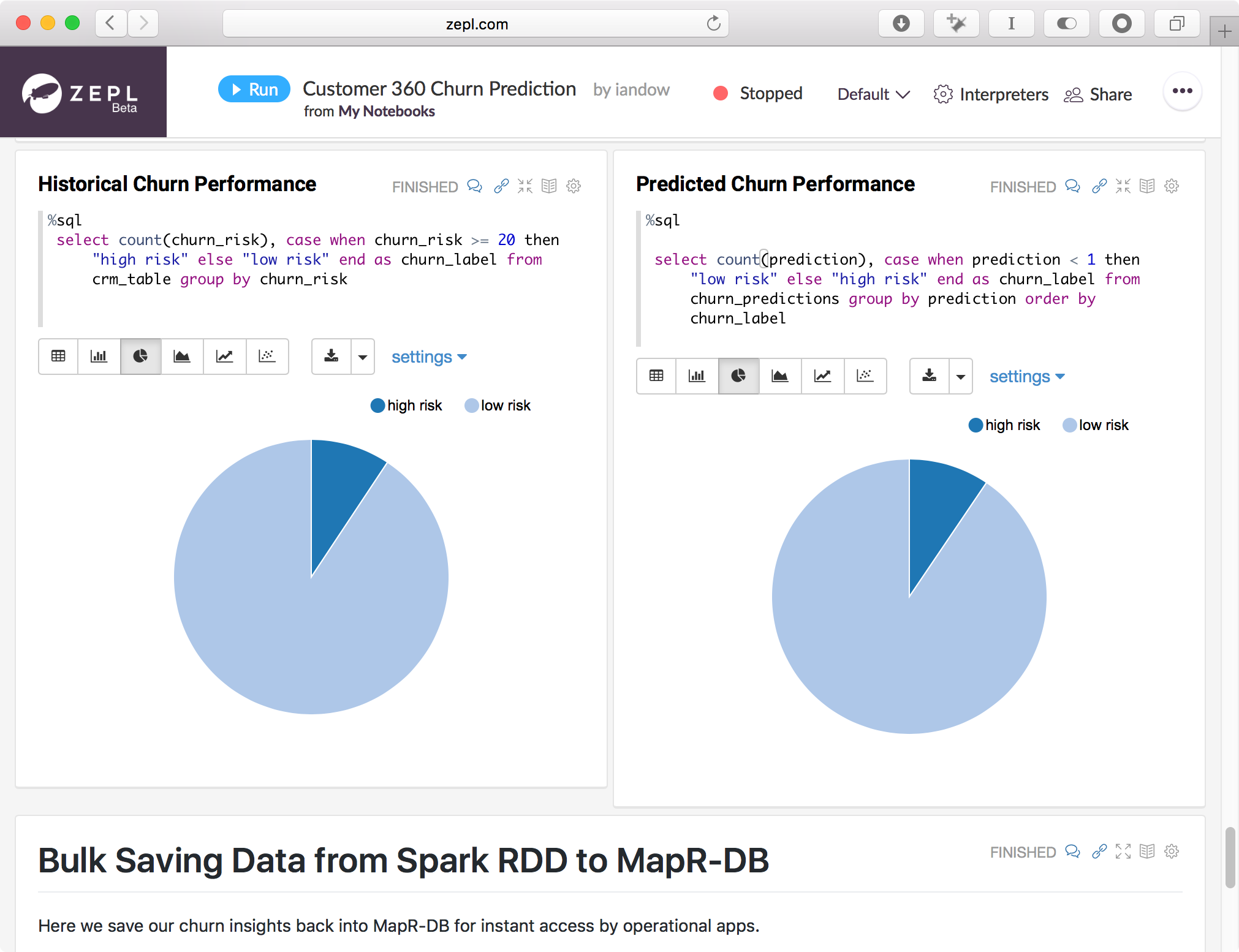
The code excerpts below show how those Spark tasks were implemented:
Loading an RDD from Mapr-DB:
// MapR-DB table returned as an RDD where each row is a JSON document
val rdd = sc.loadFromMapRDB("/mapr/my.cluster.com/tmp/crm_data").select("name", "address", "first_visit", "zip", "sentiment", "persona", "churn_risk");
println("Number of records loaded from MapR-DB: " + rdd.count)
val stringrdd = rdd.map(x => x.getDoc.asJsonString())
val crm_df = sqlContext.read.json(stringrdd)Loading an RDD from a topic in MapR Streams using the Kafka API:
case class Click(user_id: Integer, datetime: String, os: String, browser: String, response_time_ms: String, product: String, url: String) extends Serializable
val schema = StructType(Array(
StructField("user_id", IntegerType, true),
StructField("datetime", TimestampType, true),
StructField("os", StringType, true),
StructField("browser", StringType, true),
StructField("response_time_ms", StringType, true),
StructField("product", StringType, true),
StructField("url", StringType, true)
))
val groupId = "clickstream_reader"
val offsetReset = "earliest"
val pollTimeout = "5000"
val Array(topicc) = Array("/tmp/clickstream:weblog")
val brokers = "kafkabroker.example.com:9092" // not needed for MapR Streams, needed for Kafka
val ssc = new StreamingContext(sc, Seconds(2))
val topicsSet = topicc.split(",").toSet
val kafkaParams = Map[String, String](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG ->
"org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG ->
"org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> offsetReset,
ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG -> "false",
"spark.kafka.poll.time" -> pollTimeout
)
val consumerStrategy = ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams)
val messagesDStream = KafkaUtils.createDirectStream[String, String](
ssc, LocationStrategies.PreferConsistent, consumerStrategy
)
val valuesDStream = messagesDStream.map(_.value())
valuesDStream.foreachRDD { (rdd: RDD[String], time: Time) =>
// There exists at least one element in RDD
if (!rdd.isEmpty) {
val count = rdd.count
println("count received " + count)
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val df: Dataset[Click] = spark.read.schema(schema).json(rdd).as[Click]
df.show(20,false)
//The reason to use the createOrReplaceTempView( tableName ) method for a DataFrame is so that in addition to being able to use the Spark provided methods of a DataFrame, you can also issue SQL queries via the SparkSession.sql( sqlQuery ) method which use the DataFrame as a SQL table.
df.createOrReplaceTempView("weblog_snapshot")
spark.sql("select count(*) from weblog_snapshot").show
}
}
ssc.start()
ssc.awaitTerminationOrTimeout(10 * 1000)
ssc.stop(stopSparkContext = false, stopGracefully = false)Joining RDDs loaded from MapR Streams and MapR-DB:
val joinedDF = spark.sql("SELECT weblog_snapshot.datetime, weblog_snapshot.os, weblog_snapshot.browser, weblog_snapshot.response_time_ms,weblog_snapshot.product,weblog_snapshot.url, crm_table.*, case when crm_table.churn_risk >= 20 then 1 else 0 end as churn_label from weblog_snapshot JOIN crm_table ON weblog_snapshot.user_id == crm_table.user_id")Bulk Saving an RDD to MapR-DB:
// Save an RDD as a JSON file on MapR-FS
predictions_df.write.mode(SaveMode.Overwrite).format("json").save("predictions.json")
// Load an RDD from a JSON file on MapR-FS
val rdd = sc.textFile("/mapr/my.cluster.com/user/mapr/predictions.json")
// Convert an RDD[String] into JSON for the MapR-DB OJAI Connector
val maprd = rdd.map(str => MapRDBSpark.newDocument(str))
// Persist an RDD with the MapR-DB OJAI Connector
maprd.saveToMapRDB("/tmp/realtime_churn_predictions", createTable = false, bulkInsert = true, idFieldPath = "id")Please provide your feedback to this article by adding a comment to https://github.com/iandow/iandow.github.io/issues/5.
