It is rarely the case that enterprise data science applications can operate on data which is entirely contained within a single database system. Take for instance a company which wants to build a Customer 360 application that uses data sources across its enterprise to develop marketing campaigns or recommendation engines that more accurately target the concerns of key customer groups. To develop this kind of application you would be faced with a set of heterogeneous datasets such as CRM data, customer support data, and payment records that would need to be migrated and transformed into a common format simply to perform analysis. This can be challenging when your datasets are large or their schemas change, or they’re stored as schemaless CSV or JSON files.
The solution to this challenge is to use a database technology such as Apache Drill that can quickly process SQL queries across disparate datasets without moving or transforming those datasets. In this article I’m going to illustrate how Apache Drill can be used to query heterogeneous datasets easily and quickly.
What is Apache Drill?
![]()
Apache Drill is a Unix service that unifies access to data across a variety of data formats and sources. It can run on a single node or on multiple nodes in a clustered environment. It supports a variety of NoSQL databases and file systems, including HBase, MongoDB, HDFS, Amazon S3, Azure Blob Storage, and local text files like json or csv files. Drill provides the following user friendly features:
- Drill supports industry standard APIs such as ANSI SQL and JDBC
- Drill enables you to perform queries without predefining schemas
- Drill enables you to JOIN data in different formats from multiple datastores.
Connecting Drill to MySQL
Drill is primarily designed to work with nonrelational datasets, but it can also work with any relational datastore through a JDBC driver. To setup a JDBC connection follow these three steps:
- Install Drill, if you do not already have it installed.
- Copy your database’s JDBC driver into the jars/3rdparty directory. (You’ll need to do this on every node.)
- Add a new storage configuration to Drill through the web ui.
I’m using a 3 node MapR cluster for my development environment, so I already have Drill installed on each node. Drill is included in the standard MapR distribution, although MapR does not officially support the RDBMS plugin.
The MySQL JDBC connector can be downloaded from https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.41.tar.gz. So I copied that to /opt/mapr/drill/drill-1.9.0/jars/3rdparty/ on each of my nodes.
I defined the MySQL storage configuration from the Drill web ui, as show below:
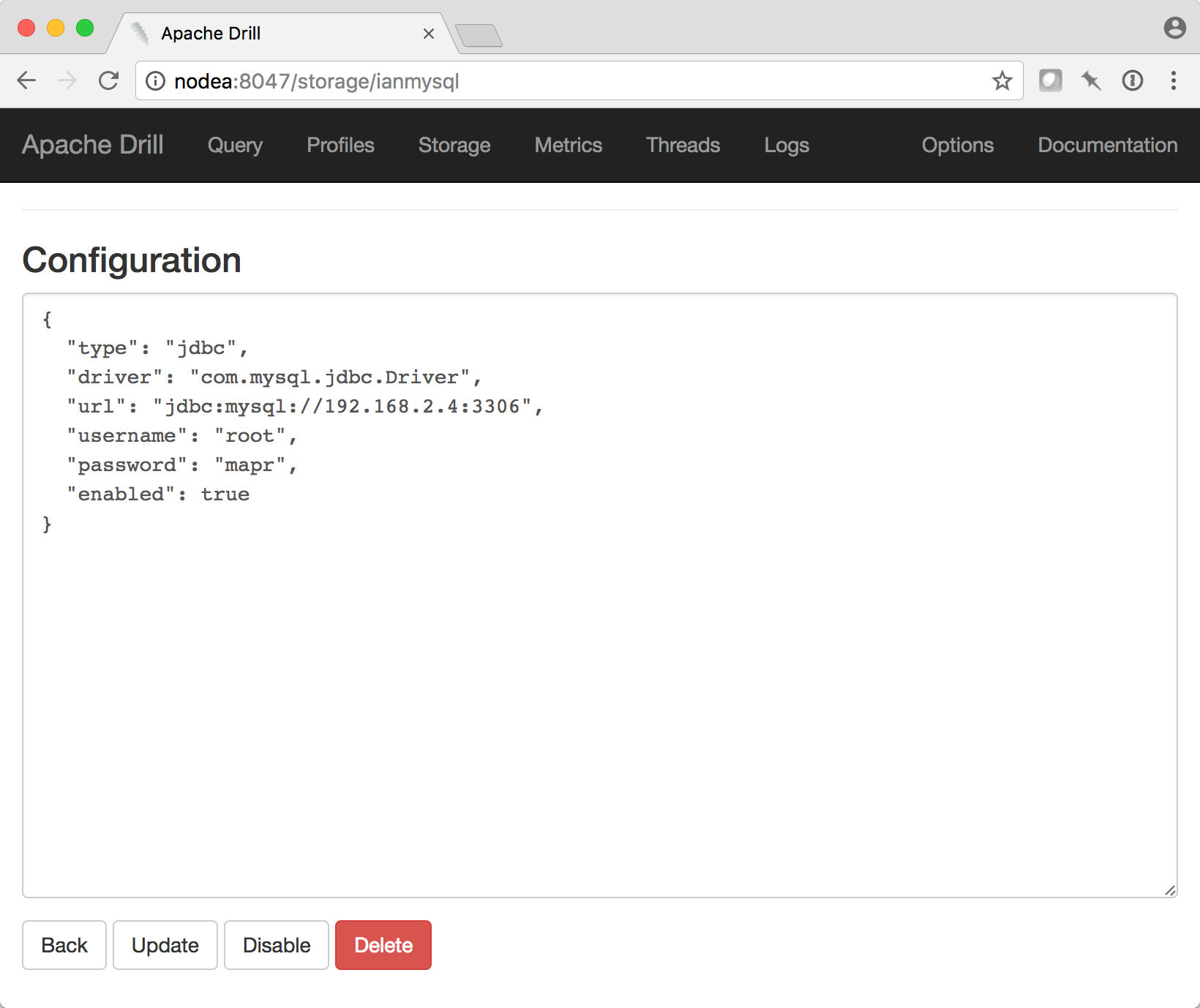
If you see the error “Please retry: error (unable to create/ update storage)” when you try to save the Storage Plugin then you’ve probably specified an invalid URL for the MySQL service or the credentials are invalid, or something else is preventing the Drill Unix service from connecting to your MySQL service.
After you click the button to enable that plugin, then you should see your MySQL tables by running show schemas in Drill, as shown below:
mapr@nodec:~$ /opt/mapr/drill/drill-*/bin/sqlline -u jdbc:drill:
apache drill 1.9.0
0: jdbc:drill:> show schemas;
+------------------------------+
| SCHEMA_NAME |
+------------------------------+
| INFORMATION_SCHEMA |
| cp.default |
| dfs.default |
| dfs.root |
| dfs.tmp |
| hbase |
| ianmysql.cars |
| ianmysql.information_schema |
| ianmysql.mysql |
| ianmysql.performance_schema |
| ianmysql |
| sys |
+------------------------------+
12 rows selected (1.195 seconds)
Here are a couple examples showing how to join JSON files with MySQL tables using a SQL JOIN in Drill:
SELECT tbl1.name, tbl2.address FROM `dfs.tmp`.`./names.json` as tbl1 JOIN `dfs.tmp`.`./addressunitedstates.json` as tbl2 ON tbl1.id=tbl2.id;SELECT tbl1.name, tbl2.address, tbl3.name FROM `dfs.tmp`.`./names.json` as tbl1 JOIN `dfs.tmp`.`./addressunitedstates.json` as tbl2 ON tbl1.id=tbl2.id JOIN ianmysql.cars.`car` as tbl3 ON tbl1.id=tbl3.customeridConnecting to Drill from Ubuntu
In order to use Drill from Python, R, or any other programming language you have to install an ODBC driver. The official Apache Drill docs describe how to install the Dron CentOS or Red Hat Linux but they do not cover Ubuntu, so I will. Here’s how to install the MapR ODBC driver on Ubuntu 14.04:
First download and install the latest MapR ODBC rpm, like this:
wget http://package.mapr.com/tools/MapR-ODBC/MapR_Drill/MapRDrill_odbc_v1.3.0.1009/maprdrill-1.3.0.1009-1.x86_64.rpm
rpm2cpio maprdrill-1.3.0.1009-1.x86_64.rpm | cpio -idmv
sudo mv opt/mapr/drill /opt/mapr/drillodbc
cd /opt/mapr/drillodbc/Setup
cp mapr.drillodbc.ini ~/.mapr.drillodbc.ini
cp odbc.ini ~/.odbc.ini
cp odbcinst.ini ~/.odbcinst.ini
# Edit the properties in those ini files according to your needs
# Put the following exports also in ~/.bashrc
export ODBCINI=~/.odbc.ini
export MAPRDRILLINI=~/.mapr.drillodbc.ini
export LD_LIBRARY_PATH=/usr/local/lib:/opt/mapr/drillodbc/lib/64:/usr/lib64Then update those .ini files, accordingly. Here is how I setup my ini files to connect to Drill:
odbc.ini:
[ODBC]
Trace=yes
Tracefile=/tmp/trace.txt
[ODBC Data Sources]
MapR Drill 64-bit=MapR Drill ODBC Driver 64-bit
[drill64]
# This key is not necessary and is only to give a description of the data source.
Description=MapR Drill ODBC Driver (64-bit) DSN
# Driver: The location where the ODBC driver is installed to.
Driver=/opt/mapr/drillodbc/lib/64/libdrillodbc_sb64.so
# The DriverUnicodeEncoding setting is only used for SimbaDM
# When set to 1, SimbaDM runs in UTF-16 mode.
# When set to 2, SimbaDM runs in UTF-8 mode.
#DriverUnicodeEncoding=2
# Values for ConnectionType, AdvancedProperties, Catalog, Schema should be set here.
# If ConnectionType is Direct, include Host and Port. If ConnectionType is ZooKeeper, include ZKQuorum and ZKClusterID
# They can also be specified on the connection string.
# AuthenticationType: No authentication; Basic Authentication
ConnectionType=Direct
HOST=nodea
PORT=31010
ZKQuorum=[Zookeeper Quorum]
ZKClusterID=[Cluster ID]
AuthenticationType=No Authentication
UID=[USERNAME]
PWD=[PASSWORD]
DelegationUID=
AdvancedProperties=CastAnyToVarchar=true;HandshakeTimeout=5;QueryTimeout=180;TimestampTZDisplayTimezone=utc;ExcludedSchemas=sys,INFORMATION_SCHEMA;NumberOfPrefetchBuffers=5;
Catalog=DRILL
Schema=
odbcinst.ini:
[ODBC Drivers]
MapR Drill ODBC Driver 32-bit=Installed
MapR Drill ODBC Driver 64-bit=Installed
[MapR Drill ODBC Driver 32-bit]
Description=MapR Drill ODBC Driver(32-bit)
Driver=/opt/mapr/drillodbc/lib/32/libdrillodbc_sb32.so
[MapR Drill ODBC Driver 64-bit]
Description=MapR Drill ODBC Driver(64-bit)
Driver=/opt/mapr/drillodbc/lib/64/libdrillodbc_sb64.so
mapr.drillodbc.ini
[Driver]
DisableAsync=0
DriverManagerEncoding=UTF-16
ErrorMessagesPath=/opt/mapr/drillodbc/ErrorMessages
LogLevel=0
LogPath=[LogPath]
SwapFilePath=/tmp
ODBCInstLib=/usr/lib/x86_64-linux-gnu/libodbcinst.so.1.0.0
Now, you need to install the Python ODBC library. See https://github.com/mkleehammer/pyodbc/wiki/Install for thorough instructions. Here’s the gist of how you install pyodbc on Ubuntu and CentOS:
Ubuntu 16.04
sudo apt install python3-pip # or `sudo apt install python-pip` for Python 2.x
sudo apt install unixodbc-dev
sudo pip3 install pyodbc # or `sudo pip install pyodbc` for Python 2.x
CentOS 7
sudo yum install epel-release
sudo yum install python-pip
sudo yum install gcc-c++
sudo yum install python-devel
sudo yum install unixODBC-devel
sudo pip install pyodbc
Finally, if you’ve installed and configured the ODBC driver correctly, then the command
python -c 'import pyodbc; print(pyodbc.dataSources()); print(pyodbc.connect("DSN=drill64", autocommit=True))'should output information like this:
```{'ODBC': '', 'drill64': '/opt/mapr/drillodbc/lib/64/libdrillodbc_sb64.so'}
<pyodbc.Connection object at 0x7f5ec4a20200>```
Connecting to Drill from Mac OS
Drill Explorer is desktop GUI for Linux, Mac OS, and Windows that’s useful for browsing data sources and previewing the results of SQL queries. People commonly use it to familiarize themselves with data sources and prototype SQL queries, then use another tool for actually analyzing that data in production.
Download and install Drill Explorer and the iODBC driver for Mac OS from here. Follow these instructions to setup the ODBC driver:
- https://drill.apache.org/docs/installing-the-driver-on-mac-os-x/
- https://drill.apache.org/docs/configuring-odbc-on-mac-os-x/
Now you should have applications available in /Applications/iODBC/ and /Applications/DrillExplorer.app/. Before you can connect Drill Explorer to Drill, first create a new connection from the iODBC Data Source Administrator. Instructions for configuring ODBC connections are at https://drill.apache.org/docs/testing-the-odbc-connection. Here’s what my configuration looks like:
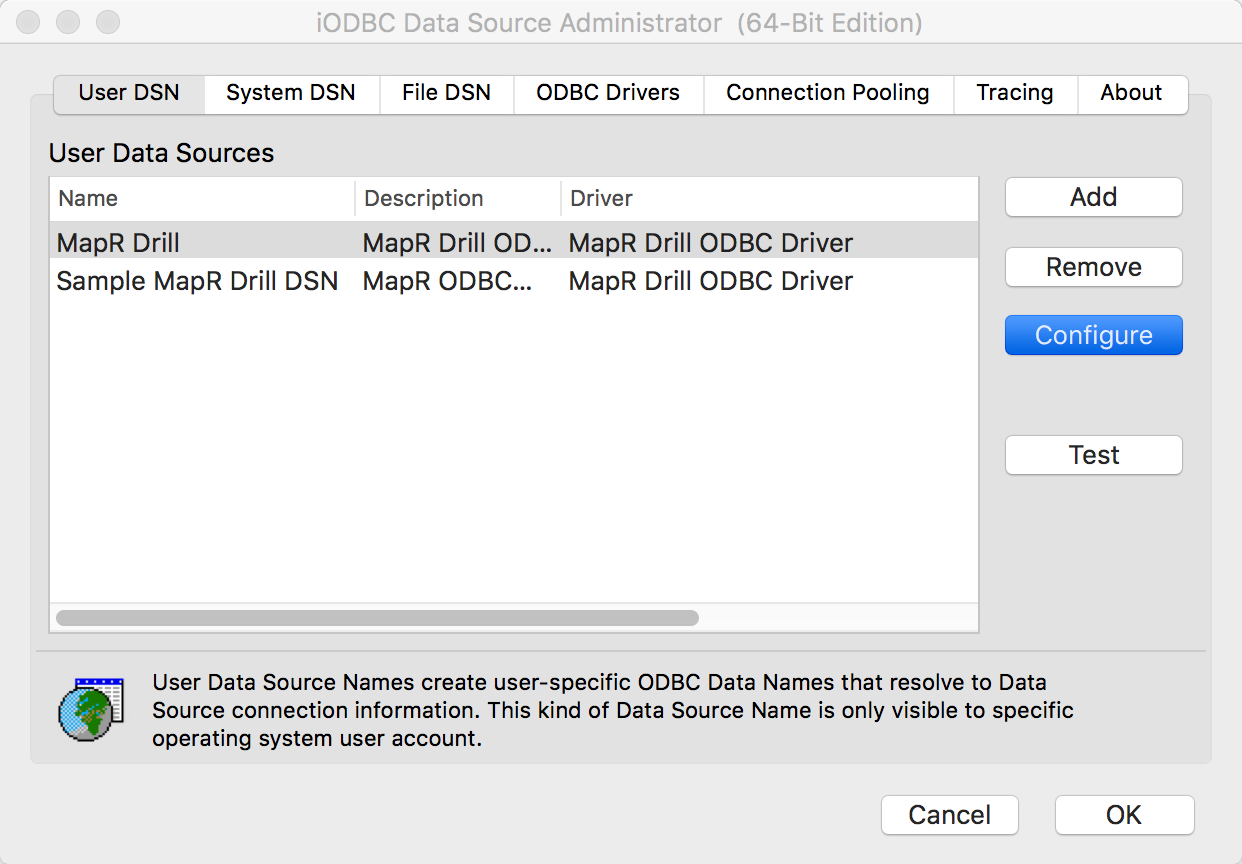
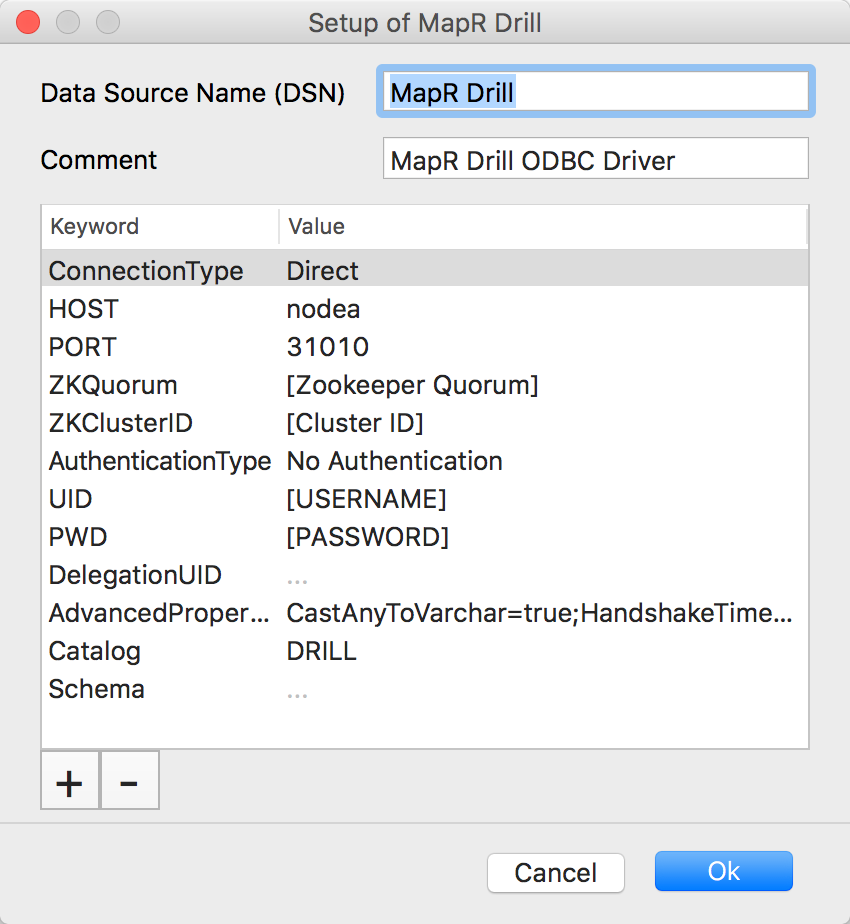
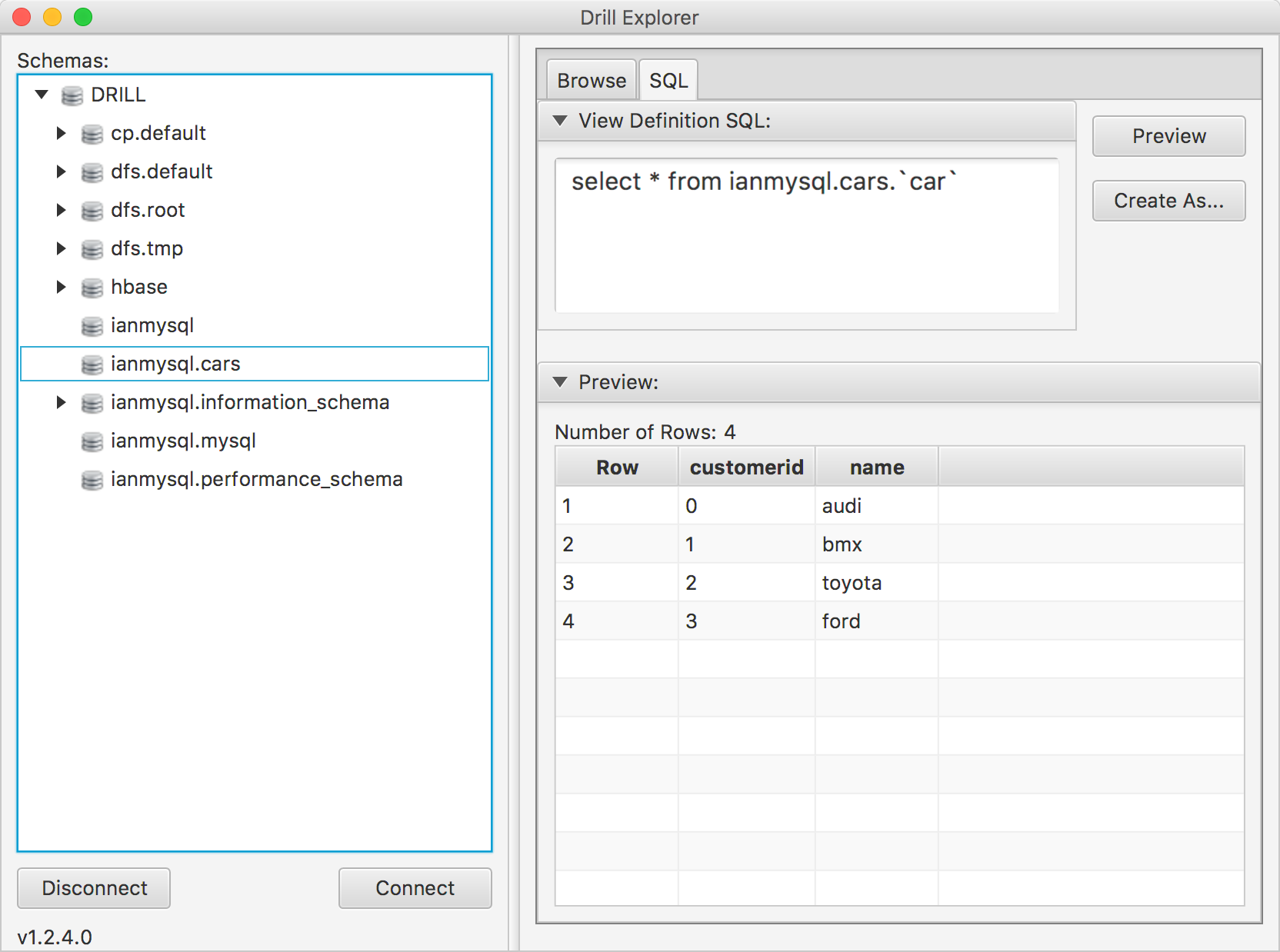
Once you connect Drill Explorer using the iODBC configuration you created, you should see all the available data sources, and preview the results of SQL queries, as shown below:
Connecting to Drill from Jupyter
You can also use the ODBC connection you configured above to programmatically query Drill data sources. MapR blogged about how to use Drill from Python, R, and Perl. I used those instructions to setup an ODBC connection in a Jupyter notebook for data exploration with Python, as shown below:
Basic Demo of Apache Drill from Jupyter¶
This notebook shows how to join relational and nonrelational datasets with Apache Drill.
# Load requisite Python libraries
import pyodbc
from pandas import *
import pandas as pd
import unicodedata
# Initialize the connection
# The DSN was defined with the iODBC Administrator app for Mac.
conn = pyodbc.connect("DSN=drill64", autocommit=True)
conn.setdecoding(pyodbc.SQL_CHAR, encoding='utf-32le', to=str)
conn.setdecoding(pyodbc.SQL_WMETADATA, encoding='utf-32le', to=str)
cursor = conn.cursor()
# Setup a SQL query to select data from a csv file.
# The csv2 filename extension tells Drill to extract
# column names from the first row.
s = "SELECT * FROM `dfs.tmp`.`./companylist.csv2` limit 3"
# Execute the SQL query
pandas.read_sql(s, conn)
Connecting to Drill from R Studio
You can also connect to Drill from R Studio using the ODBC connection you configured above. Here’s how I set that up:
Download and install the RODBC driver:
brew update
brew install unixODBC
wget "https://cran.r-project.org/src/contrib/RODBC_1.3-13.tar.gz"
R CMD INSTALL RODBC_1.3-13.tar.gzSet your LD_LIBRARY_PATH:
export LD_LIBRARY_PATH=/usr/local/iODBC/lib/Open R Studio and submit a SQL query
library(RODBC)
ch<-odbcConnect("Sample MapR Drill DSN")
sqlQuery(ch, 'use dfs.tmp')
sqlQuery(ch, 'show files')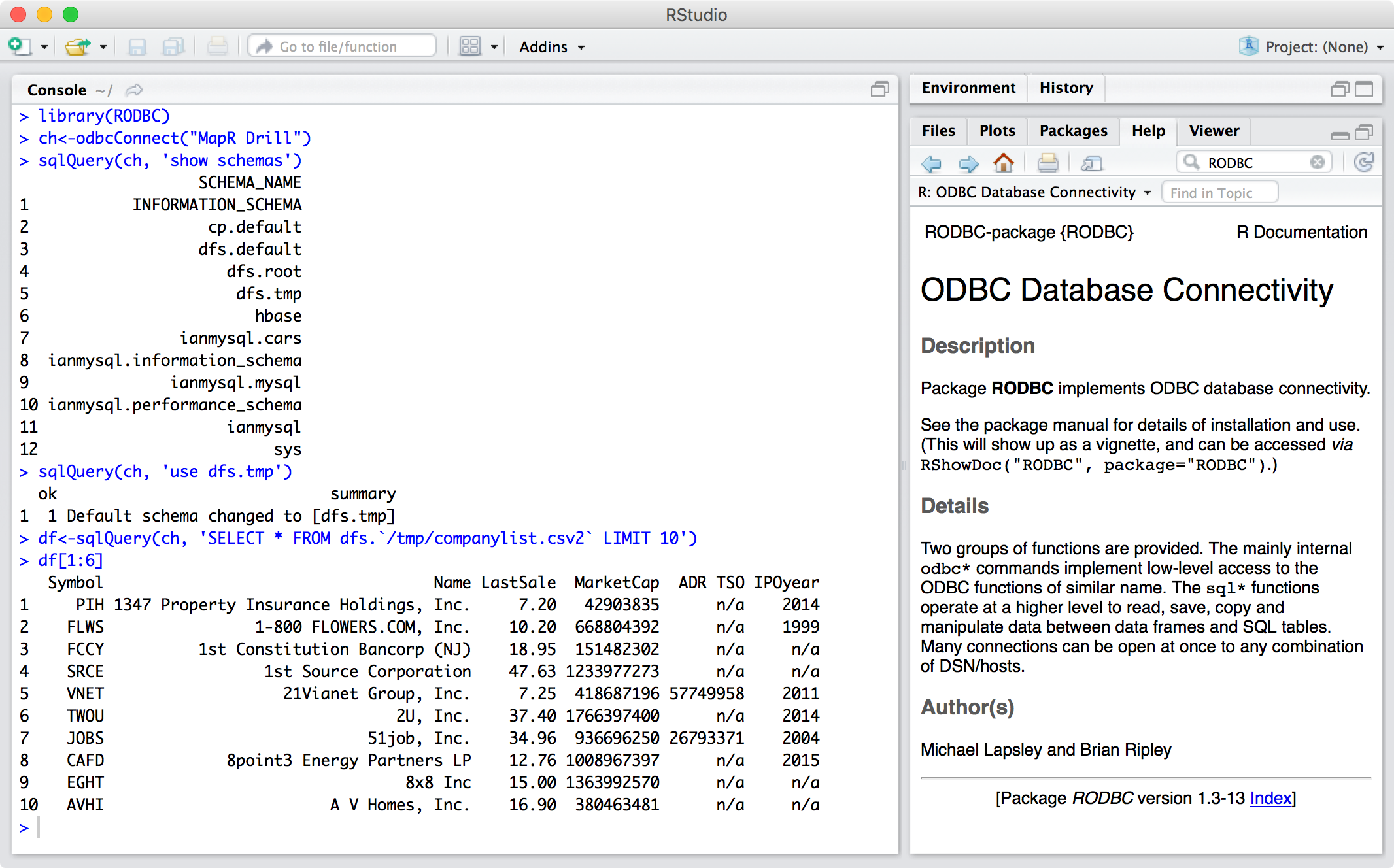
For more information on using Drill with R, check out the following references:
- http://stackoverflow.com/questions/28081640/installation-of-rodbc-on-os-x-yosemite
- https://community.mapr.com/thread/9942
Common problems
F**‘ing Unicode!
Dealing with unicode in the python ODBC driver has caused me a lot of frustration. Fortunately, specifying unicode decoding options as shown below seems to help.
conn = pyodbc.connect("DSN=drill64", autocommit=True)
# Set unicode options so the ODBC driver returns column names and table contents as ASCII strings
conn.setdecoding(pyodbc.SQL_CHAR, encoding='utf-32le', to=str)
conn.setdecoding(pyodbc.SQL_WMETADATA, encoding='utf-32le', to=str)
cursor = conn.cursor()
s = "show schemas`"
df = pandas.read_sql(s, conn)
list(df)
That should output
['SCHEMA_NAME']
If you don’t set the unicode options, as shown above, then you’ll see this instead:
[u'S\x00C\x00H\x00E\x00M\x00A']
You can convert that to ascii with something like, print(list(data)[0].decode("utf-8")), but I find that really confusing. Setting the following unicode options for the ODBC connection will ensure ODBC returns ASCII column names and dataframe values instead of unicode:
conn.setdecoding(pyodbc.SQL_CHAR, encoding='utf-32le', to=str)
conn.setdecoding(pyodbc.SQL_WMETADATA, encoding='utf-32le', to=str)
Unicode errors with Anaconda
The unicode options I just mentioned don’t seem to work with Anaconda. You’ll know this if the statements you run under pyodbc in Anaconda look like this under the Drillbit GUI:
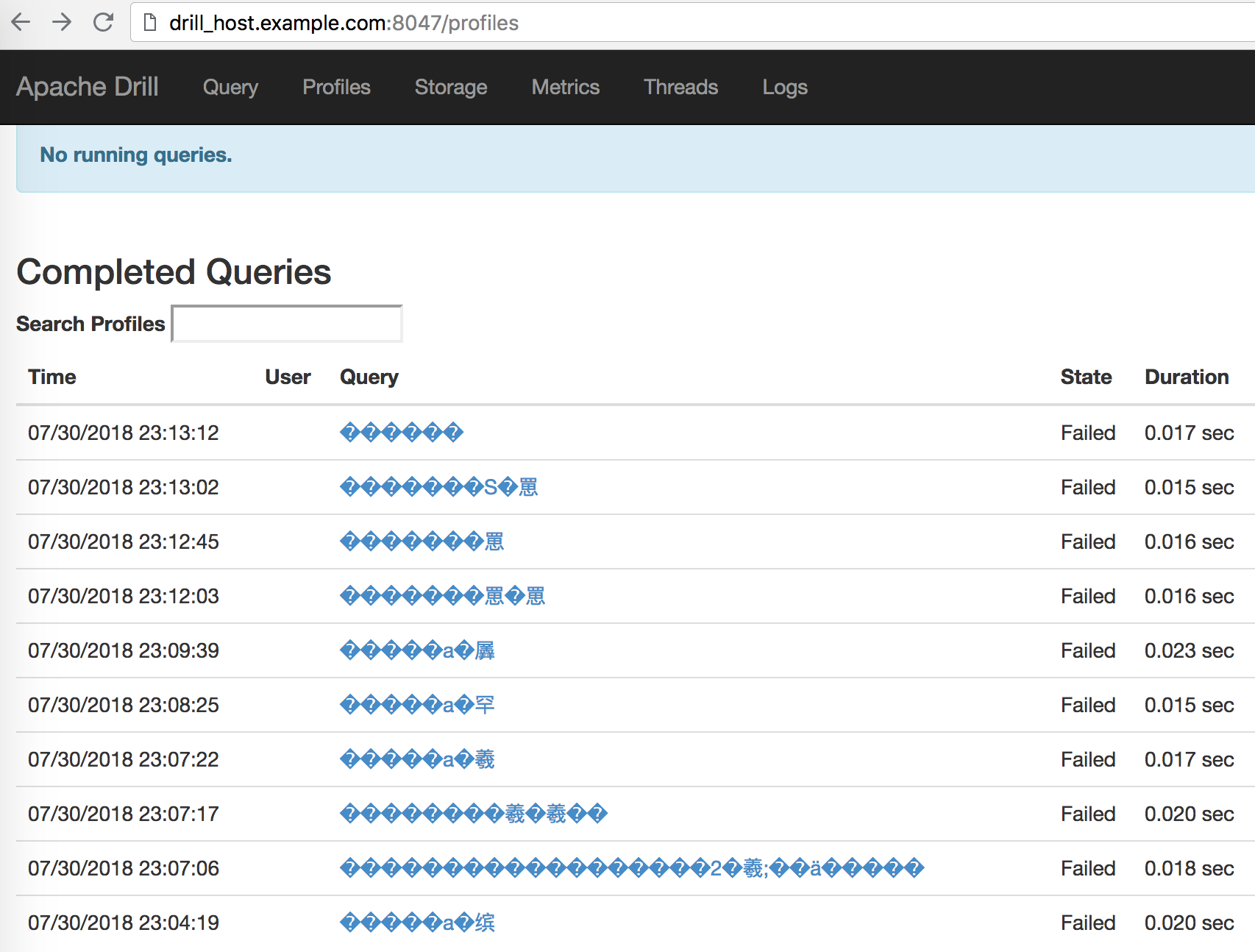
Fortunately, running conn.setencoding("utf-8"); seems to fix this problem. For example:
python -c 'import pandas; import pyodbc; print(pyodbc.dataSources()); conn=pyodbc.connect("DSN=drill64", autocommit=True); conn.setencoding("utf-8"); cursor = conn.cursor(); print(cursor); print(pandas.read_sql("show schemas", conn))'
Errors about ‘/opt/mapr/drillodbc/lib/64/libdrillodbc_sb64.so’
I like to test python’s access to Drill via the ODBC driver with a command like this:
python -c 'import pandas; import pyodbc; print(pyodbc.dataSources()); conn=pyodbc.connect("DSN=drill64", autocommit=True); cursor = conn.cursor(); print(cursor);'
If it works, you should see something like this:
{'ODBC': '', 'drill64': '/opt/mapr/drillodbc/lib/64/libdrillodbc_sb64.so'}
Often I’ll get this error:
Traceback (most recent call last):
File "<string>", line 1, in <module>
pyodbc.Error: ('01000', u"[01000] [unixODBC][Driver Manager]Can't open lib '/opt/mapr/drillodbc/lib/64/libdrillodbc_sb64.so' : file not found (0) (SQLDriverConnect)")
If you get that error, run this command to figure out what file is not found:
ldd /opt/mapr/drillodbc/lib/64/libdrillodbc_sb64.so
If you see this:
libdrillClient.so => not found
then that means you need to add /opt/mapr/drillodbc/lib/64 to your LD_LIBRARY_PATH, like this:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/mapr/drillodbc/lib/64
```
The ODBC driver seems to return column names and table contents as unicode.
Conclusion
What I’ve tried to show above is that it doesn’t matter how your data is formatted or where its stored, Apache Drill enables you to easily query and combine datasets from a wide variety of databases and file systems. This makes Apache Drill an extremely valuable tool for applications such as Customer 360 applications that require access to disparate datasets and the ability to combine those datasets with low latency SQL JOINs.
Please provide your feedback to this article by adding a comment to https://github.com/iandow/iandow.github.io/issues/2.
