A lot of people choose MapR as their core platform for processing and storing big data because of its advantages for speed and performance. MapR consistently performs faster than any other big data platform for all kinds of applications, including Hadoop, distributed file I/O, NoSQL data storage, and data streaming. In this post, I’m focusing on the latter to provide some perspective on how much better/faster/cheaper MapR Streams can be compared to Apache Kafka as a data streaming technology.
MapR Streams is a cluster-based messaging system for streaming data at scale. It’s integrated into the MapR Converged Data Platform and implements the Apache Kafka Java API so applications written for Kafka can also run on MapR Streams. What differentiates the MapR Streams technology from Kafka are its built-in features for global replication, security, multi-tenancy, high availability, and disaster recovery—all of which it inherits from the MapR Converged Data Platform. From an operational perspective, these features make MapR Streams easier to manage than Kafka, but there are speed advantages, too. I’ve been looking at this a lot lately, trying to understand where and why MapR Streams outperforms Kafka. In this blog post, I will share with you how clearly MapR Streams can transport a much faster stream of data, with much larger message sizes, and to far more topics than what can be achieved with Kafka.
Test Strategy
In this study, I wanted to compare Kafka and MapR Streams as to how they perform “off the shelf” without the burden of tuning my test environment to perfectly optimize performance in each test scenario. So, I have pretty much stuck with the default settings for services and clients. The only exceptions are that I configured each Kafka topic with a replication factor of 3 and configured producers to send messages synchronously, since these are the default modes for MapR Streams. I also disabled stream compression in order to control message sizes and measure throughput more precisely.
Test Configurations
I measured performance from both producer and consumer perspectives. However, consumers run faster than producers, so I focused primarily on the producer side since the throughput of a stream is bounded by the throughput of its producers. I used two threads in my producer clients so that message generation could happen in parallel with sending messages and waiting for acknowledgments. I used the following properties for producers and topics:
acks = all
batch.size = 16384
latency.ms = 0ms
block.on.buffer.full = true
compression = none
default.replication.factor = 3My test environment consisted of three Ubuntu servers running Kafka 2.11-0.10.0.1 or MapR 5.2 on Azure VMs sized with the following specs:
- Intel Xeon CPU E5-2660 2.2 GHz processor with 16 cores
- SSD disk storage with 64,000 Mbps cached / 51,200 uncached max disk throughput
- 112GB of RAM
- Virtual networking throughput between 1 and 2 Gbits/sec (I measured this quantitatively since I couldn’t easily find virtual network throughput specs from Microsoft).
Performance Metrics
Throughput, latency, and loss are the most important metrics measuring the performance of a message bus system. MapR Streams and Kafka both guarantee zero loss through at-least-once semantics. MapR provides some advantages when it comes to latency, but typically both MapR Streams and Kafka deliver messages sufficiently quick for real-time applications. For those reasons, I chose to focus on throughput in this study.
Throughput is important because if an application generates messages faster than a message bus can consume and deliver them, then those messages must be queued. Queueing increases end-to-end latency and destabilizes applications when queues grow too large.
Furthermore, throughput in Kafka and MapR Streams is sensitive to the size of the messages being sent and to the distribution of those messages into topics. So, I analyzed those two attributes independently in order to measure how message size and stream topics affect throughput.
Throughput Performance
To measure producer throughput, I measured how fast a single producer could publish a sustained flow of messages to single topic with 1 partition and 3x replication. I ran this test for a variety of message sizes to see how that affects throughput. The results show MapR Streams consistently achieving much higher throughput than Kafka and having a much higher capacity for handling large message sizes, as shown below.
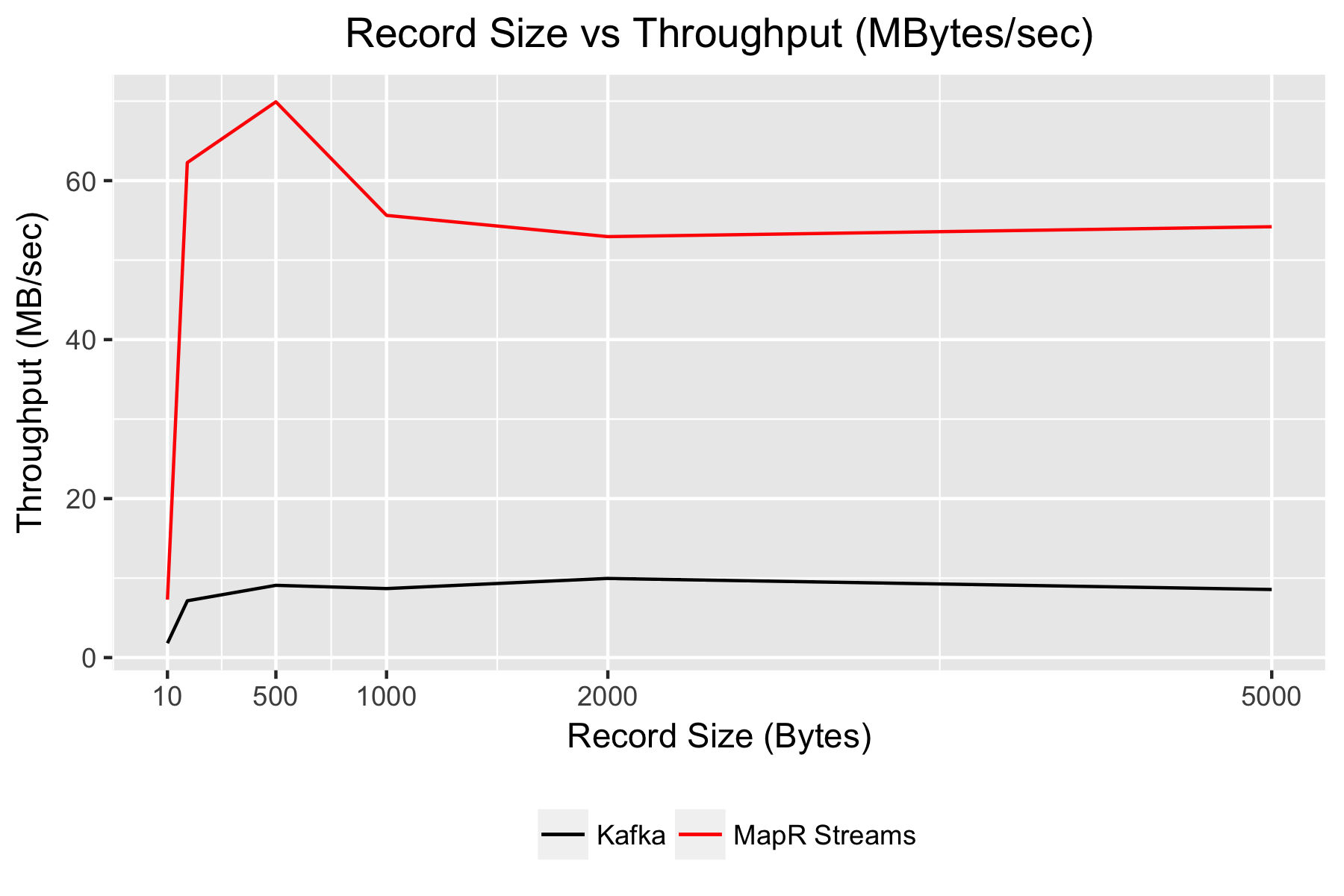
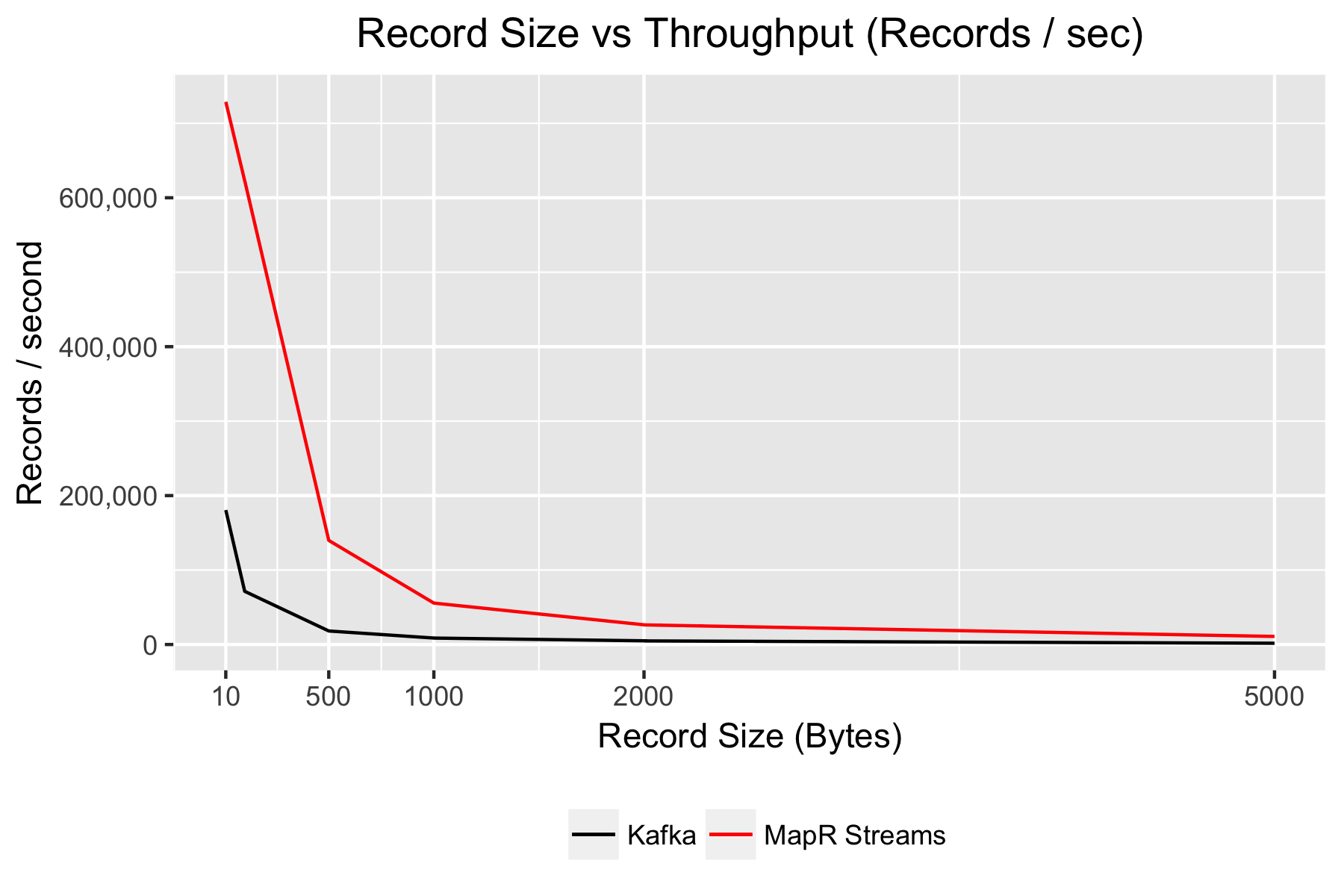
MapR Streams doesn’t just send a faster volume of data than Kafka; it also has the capacity to send more records per second. We can see this by plotting throughput in terms of raw record count, as shown below:
I recorded these results with two different code bases. First, I used custom tests that I wrote using the Java unit test framework (JUnit), then I used the performance test scripts included with Kafka and MapR. These different approaches did not produce exactly the same results but they were close, as shown below. This correlation helps validate the conclusions stated above, that MapR Streams can transport a larger volume of data and more frequent messages than Kafka.
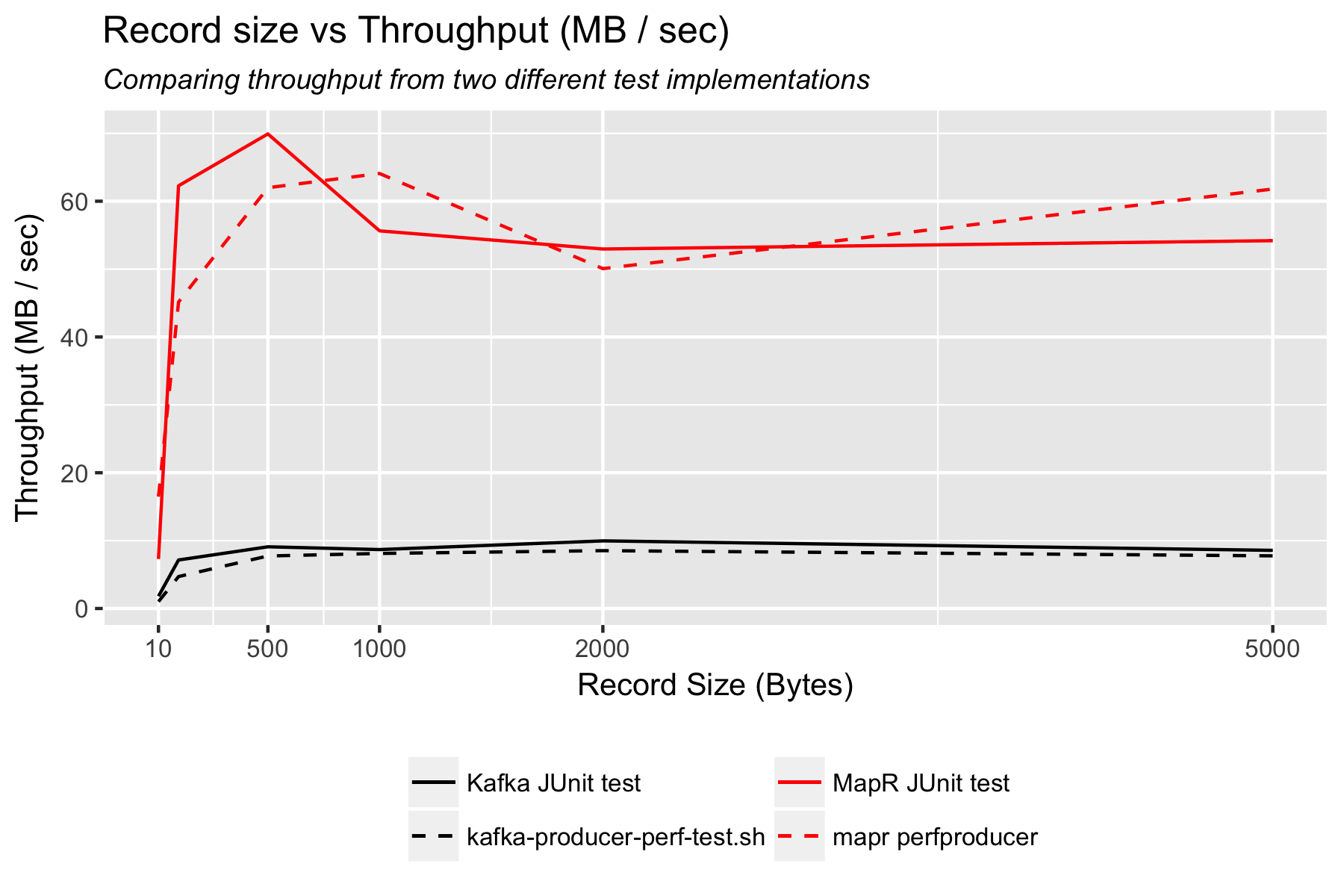
How does MapR achieve more than 4x throughput than Kafka?
There are a lot of reasons why MapR Streams is faster, and without getting too technical, I’ll mention just a few. First, the MapR Streams client more efficiently flushes data to the MapR Streams server. It spawns its own threads to do this work, whereas Kafka uses the client application threads directly to flush to a Kafka broker, which in many cases is limited to just a single thread.
On the server side, MapR Streams inherits efficient I/O patterns from the core MapR storage layer which keeps files coherent and clean so that I/O operations can be efficiently buffered and addressed to sequential locations on disk. Replication is more efficient, too, since the underlying MapR storage platform has distributed synchronous replication built in, along with other operational features that simply don’t exist in Kafka, such as snapshots, mirroring, quotas, access controls, etc.
How to replicate this test
My JUnit tests for benchmarking Kafka and MapR Streams is available at https://github.com/iandow/kafka_junit_tests. Here are the commands that I used to generate the data shown above:
git clone https://github.com/iandow/kafka_junit_tests
cd kafka_junit_tests
# Create a Kafka topic...
/opt/kafka_2.11-0.10.0.1/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic t-00000 --config compression.type=uncompressed
# or create a MapR Streams topic.
maprcli stream create -path /user/mapr/iantest -produceperm p -consumeperm p -topicperm p -defaultpartitions 1 -compression off
# Then compile.
mvn -e -Dtest=MessageSizeSpeedTest test
# Test data will be saved in size-count.csvYou can also measure throughput using the performance test utilities included with Kafka and MapR. Here are the commands that I used to do that:
Kafka script:
https://gist.github.com/iandow/bf5df0f9b4f19e6a19aa5a7a93b7c81c
MapR script:
https://gist.github.com/iandow/0750185f1d3631301d476b426c109a50
Topic Scalability
Another major advantage that MapR Streams holds over Kafka relates to how well it can handle large quantities of stream topics. Topics are the primary means of organizing stream data; however, there is overhead associated with categorizing streams into topics, and producer throughput is sensitive to that overhead. I quantified this by measuring how fast a single producer could publish a sustained flow of messages to an increasingly large quantity of topics. This is essentially a “fan-out” producer (illustrated below) and it is very common for fast data pipelines to use this pattern so that data can be more easily consumed downstream.

Each of the topics created for this scenario were configured with a single partition and 3x replication. Record size was held constant at 100 bytes.
It’s clear from the following graph that MapR Streams scales to a larger quantity of topics than Kafka.
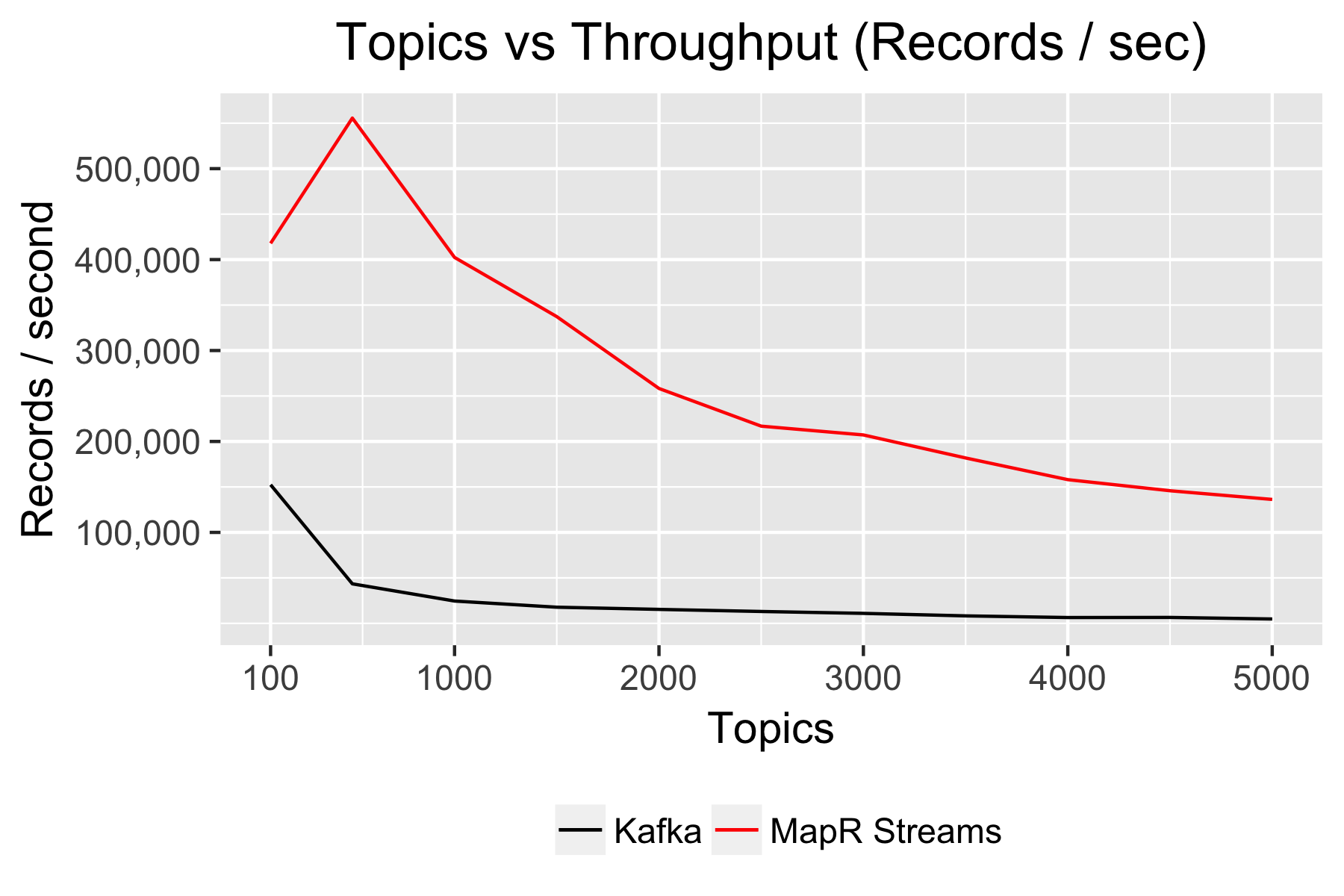
How does MapR handle so many more topics than Kafka?
A topic is just metadata in MapR Streams; it does not introduce overhead to normal operations. MapR Streams uses only one data structure for a stream, no matter how many topics it has, and the MapR storage system provides extremely fast and scalable storage for that data.
On the other hand, Kafka represents each topic by at least one directory and several files in a general purpose file system. The more topics/partitions Kafka has the more files it creates. This makes it harder to buffer disk operations, perform sequential I/O, and it increases the complexity of what ZooKeeper must manage.
How to replicate this test
This scenario can be run with another JUnit test from https://github.com/iandow/kafka_junit_tests, as follows:
git clone https://github.com/iandow/kafka_junit_tests
cd kafka_junit_tests
# For MapR only, create the stream first:
maprcli stream create -path /user/mapr/taq -produceperm p -consumeperm p -topicperm p -compression off
mvn -e -Dtest= ThreadCountSpeedTest test
# Test data will be saved in thread-count.csvPartition Scalability
Stream topics are often subdivided into partitions in order to allow multiple consumers to read from a topic simultaneously. Both Kafka and MapR Streams allow topics to be partitioned, but partitions in MapR Streams are much more powerful and easier to manage than partitions in Kafka. For example, Kakfa requires partitions to fit within the disk space of a single cluster node and cannot be split across machines. MapR Streams is not limited by the storage capacity of any one node because the MapR storage system automatically grows (or shrinks) partitions across servers. I’ll talk more about these operational advantages later, but let’s consider the performance implications of partitioning now.
ZooKeeper elects separate nodes to be leaders for each partition. Leaders are responsible for processing the client reads and writes for their designated partition. This helps load balance client requests across the cluster, but it complicates the work the ZooKeeper must do to keep topics synchronized and replicated. Leader election takes time and does not scale well. In my tests, I saw leader election take at least 0.1 seconds per partition and it ran serially. So, for example, it would take more than 10 seconds to configure a topic with 100 partitions, that is, if ZooKeeper didn’t crash, which it frequently did when I created topics with 100 or more partitions.
In MapR Streams, I had no problem streaming data to topics with thousands of partitions, as shown below. This graph shows the throughput for a producer sending synchronously to a 3x replicated topic subdivided into an increasingly large number of partitions. I could not run my test in Kafka beyond 400 partitions, so that line is cut short.
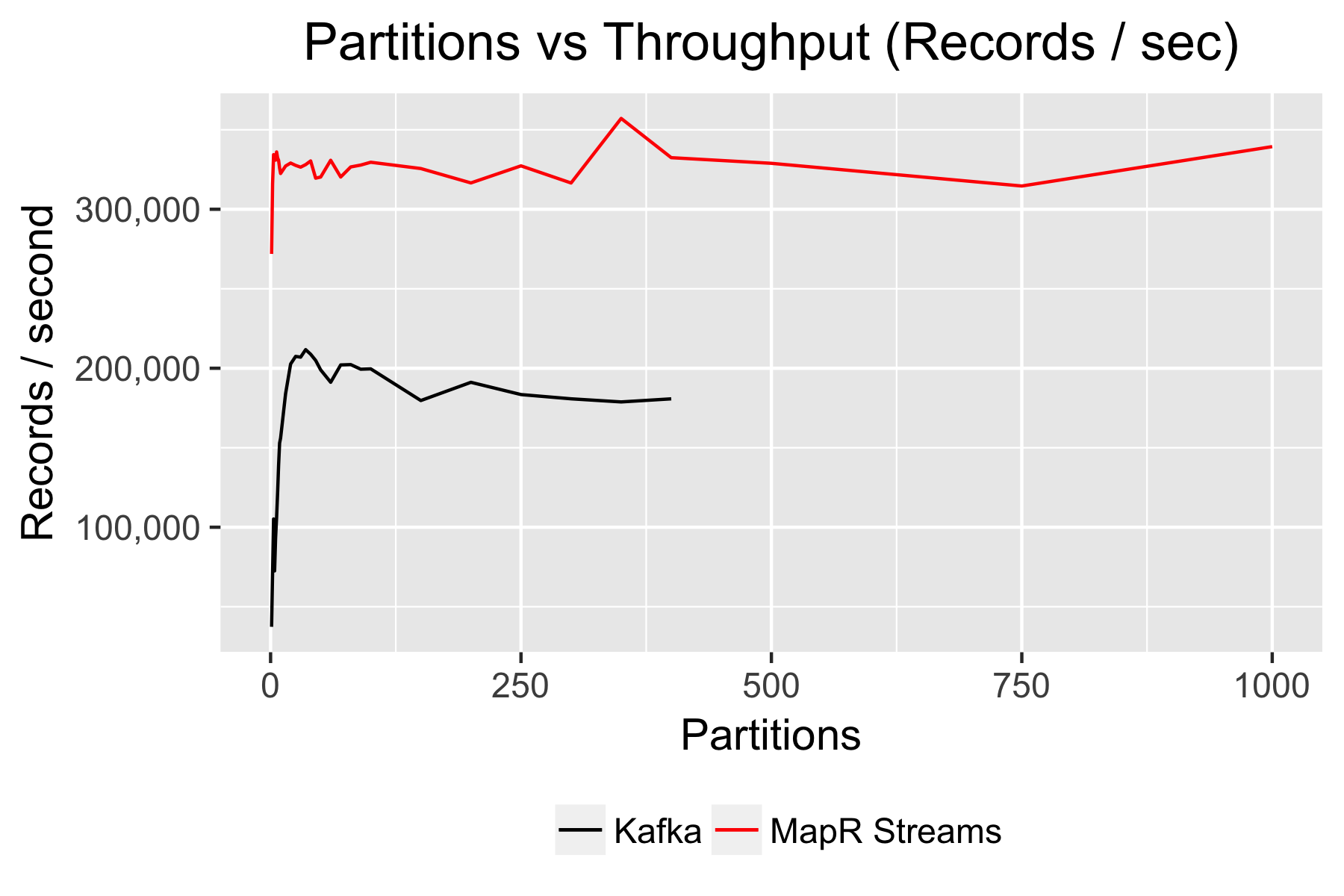
How to replicate this test
I used the performance scripts included with Kafka and MapR to generate the partition vs. throughput data shown above. Here is the script I used to run this test in Kafka:
https://gist.github.com/iandow/625d783333a53b592f0381e6b37ee9ab
That script will silently freeze if ZooKeeper fails, but it will continue once ZooKeeper starts again. So in another terminal, I simultaneously ran the following script to automatically restart ZooKeeper if it fails (which it is likely to do during this test):
https://gist.github.com/iandow/2dc07bde132669706467e8ee45507561
Here is the script I used to generate partitions vs. throughput data in MapR:
https://gist.github.com/iandow/8074962f6205552c9cdc3fceccdd9793
Operational Advantages for MapR Streams
Increasing throughput capacity and decreasing message latency can often be accomplished simply by adding nodes to your distributed messaging cluster. However, doing so costs money and complicates management, so essentially saying that MapR Streams performs better than Kafka is another way of saying that operating a distributed messaging platform can be done with less hardware on MapR than with Kafka.
However, unless you’re working on applications that scale to extreme lengths, then the challenges you face with Kafka are more likely to be operational rather than performance in nature. And this is where the MapR total cost of ownership really shines.
Not only does MapR Streams execute with higher performance, it also addresses major operational deficiencies in Kafka. Here are three examples relating to replication, scaling, and mirroring:
- Kafka requires that the MirrorMaker processes be manually configured in order to replicate across clusters. Replication is easy to configure with MapR Streams and supports unique capabilities for replicating streams across data centers and allowing streams to be updated in multiple locations at the same time.
- Kafka’s mirroring design simply forwards messages to a mirror cluster. The offsets in the source cluster are useless in the mirror, which means consumers and producers cannot automatically failover from one cluster to a mirror. MapR continuously transfers updated records for near real-time replication and preserves message offsets in all replicated copies.
- Kakfa requires partitions to fit within the disk space of a single cluster node and cannot be split across machines. This is especially risky, because ZooKeeper could automatically assign multiple large partitions to a node that doesn’t have space for them. You can move them manually, but that can quickly become unmanageable. MapR Streams is not limited by the storage capacity of any one node because it distributes stream data across the cluster.
References
For more information about the operational advantages of MapR Streams, see Will Ochandarena’s blog post, Scaling with Kafka – Common Challenges Solved.
I also highly recommend reading Chapter 5 of Streaming Architecture: New Designs Using Apache Kafka and MapR Streams, by Ted Dunning & Ellen Friedman.
Conclusion
MapR Streams outperforms Kafka in big ways. I measured the performance of distributed streaming in a variety of cases that focused on the effects of message size and topic quantity, and I saw MapR Streams transport a much faster stream of data, with much larger message sizes, and to far more topics than what could be achieved with Kafka on a similarly sized cluster. Although performance isn’t the only thing that makes MapR Streams desirable over Kafka, it offers one compelling reason to consider it.
