Streaming data is like, “Now you see it. Now you don’t!”
One of the challenges when working with streams, especially streams of fast data, is the transitory nature of the data. Kafka streams are characterized by a retention period that defines the point at which messages will be permanently deleted. For many applications, such as those fed by streams of rapidly generated sensor data, the retention period is a desirable and convenient way to purge stale data, but in other cases, such as with insurance or banking applications, record-retention laws may require data to be persisted far beyond the point at which that data has any practical value to streaming analytics. This is challenging in situations where rapidly ingested data creates pressure on stream consumers designed to write streaming records to a database. Even if we can ensure these consumers keep up, we still need to guarantee zero data loss in the unlikely event that they do fail.
MapR Streams and MapR-DB work together to provide a scalable and fault tolerant way to save streaming data in long-term storage. They both have a distributed, scale-out design based on the MapR Converged Data Platform. Furthermore, as a NoSQL data store MapR-DB makes it easy to persist data with the same schema encoded into streams. This is not only convenient for the developer but also minimizes the work required to transform streaming records into persistable objects.
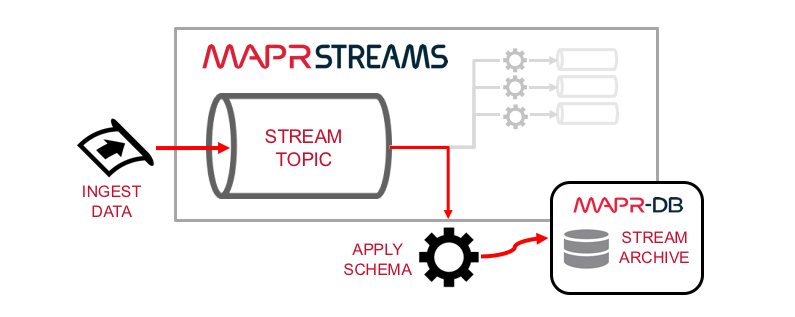
Let’s illustrate these concepts with an example that persists streaming data in 5 simple steps:
- Setup stream and database connections.
- Consume records from a MapR stream using the standard Kafka API.
- Convert each consumed record to a JSON object.
- Persist that JSON object in MapR-DB.
- Update the stream cursor to ensure graceful recovery should a stream consumer fail.
Step 1: Setup stream and database connections
Before we can do anything interesting we first have to setup our stream and database connections. We’ll use the following two options that relate to fault tolerance:
- We disable the
enable.auto.commitconsumer option in order to commit stream cursors only after their corresponding records have been writing to the database. - We disable the
BUFFERWRITEtable option in order to ensure database writes are not buffered on the client. With these options we’re sacrificing speed for higher fault tolerance but we can compensate for that tradeoff by creating more topic partitions and running more concurrent consumers in parallel.
So, here is what our database and consumer configurations look like:
Table table;
String tableName = "/user/mapr/ticktable";
if (MapRDB.tableExists(tableName)) {
table = MapRDB.getTable(tableName);
} else {
table = MapRDB.createTable(tableName);
}
table.setOption(Table.TableOption.BUFFERWRITE, false);
Properties props = new Properties();
props.put("enable.auto.commit","false");
props.put("group.id", “mygroup”);
props.put("auto.offset.reset", "earliest");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<String, String>(props);
List<String> topics = new ArrayList<>();
topics.add(topic);
consumer.subscribe(topics);Step 2: Consume records from the stream
To consume records from a stream, you first poll the stream. This gives you a collection of ConsumerRecords which you then iterate through in order to access each individual stream record. This is standard Kafka API stuff, and it looks like this:
ConsumerRecords<String, byte[]> records = consumer.poll(TIMEOUT);
Iterator<ConsumerRecord<String, byte[]>> iter = msg.iterator();
while (iter.hasNext())
{
ConsumerRecord<String, byte[]> record = iter.next();
}Step 3: Convert streamed records to JSON
Before we write consumer records to the database, we need to put each record in a format that has columns. In our example we’re streaming byte arrays, which by themselves have no field related attributes, so we need to convert these byte arrays into a type containing attributes that will correspond to columns in our database. We’ll do this with a Java object, defined in Tick.java, which uses the @JsonProperty annotation to conveniently convert Tick objects encoded as byte arrays into a JSON document, like this:
Tick tick = new Tick(record.value());
Document document = MapRDB.newDocument((Object)tick);Step 4: Persist the JSON document to MapR-DB
This part is easy. We can insert each JSON document as a new row to a table in MapR-DB with one line of code, like this:
table.insertOrReplace(tick.getTradeSequenceNumber(), document);The first parameter in the insertOrReplace method is Document ID (or rowkey). It’s a property of our dataset that the value returned by tick.getTradeSequenceNumber() is unique for each record, so we’re referencing that as the Document ID for our table insert in order to avoid persisting duplicate records even if duplicate messages are consumed from the stream. This guarantees idempotency in our stream consumer.
Step 5: Update the stream cursor
Finally, we’ll update the cursor in our stream topic. In the unlikely event that our stream consumer fails, this ensures that a new consumer will be able to continue working from where the last consumer left off.
consumer.commitSync();How do I query MapR-DB tables?
Now that we have data persisted in MapR-DB tables, how can I query it?
My MapR-DB table is named /user/mapr/ticktable, which on the filesystem is located at /mapr/ian.cluster.com/user/mapr/ticktable. First I’ll show how to query this table with MapR dbshell, then with Apache Drill.
Here’s how I read it with dbshell:
mapr dbshell
find /user/mapr/ticktableHere’s how I read it with Drill:
/opt/mapr/drill/drill-1.6.0/bin/sqlline -u jdbc:drill:Either of the following two SELECT statements will work:
SELECT * FROM dfs.`/mapr/ian.cluster.com/user/mapr/ticktable`;
SELECT * FROM dfs.`/user/mapr/ticktable`;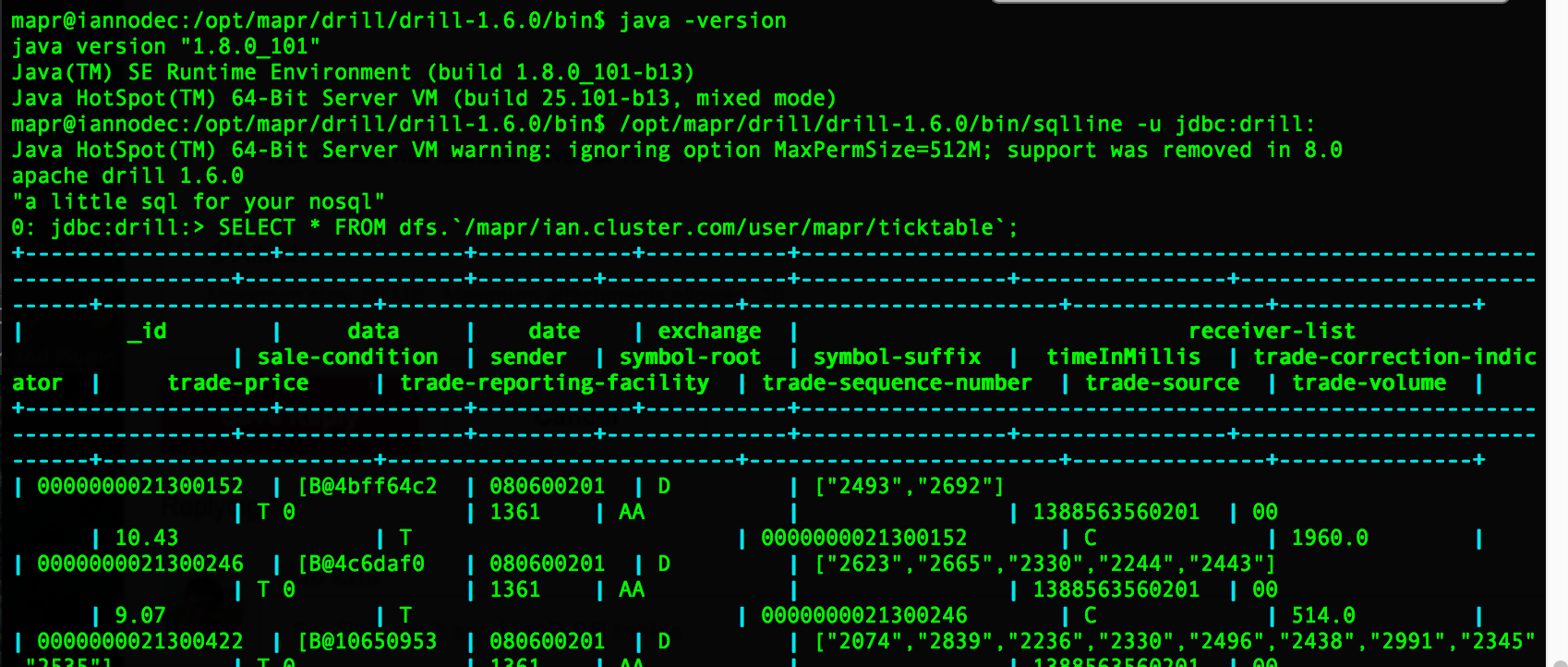
Summary
The design we just outlined provides a highly scalable approach to persisting stream data. It ensures thread-safety by processing immutable stream data with idempotent stream consumers and achieves fault tolerance by updating stream cursors only after records have been persisted in MapR-DB. This represents an elastic, responsive, resilient, and message-driven design consistent with the characteristics of reactive microservices. This is a reliable approach to persisting Kafka streams in long-term NoSQL storage.
If you’d like to see a complete example application that uses the techniques described in this post, check out the Persister.java on GitHub.
References
Here are some useful links to APIs and utilities I used above:
