Finding the optimal set of configurations for Kafka in order to achieve the fastest possible throughput for real time/stream analytics can be a time-consuming process of trial and error. Automating that process with parametrized JUnit tests can be an excellent way to find optimal Kafka configurations without guess work and without wasting time.
What factors impact Kafka performance?
Apache Kafka is a distributed streaming platform. It lets you publish and subscribe to streams of data like a messaging system. You can also use it to store streams of data in a distributed cluster and process those streams in real-time. However, sometimes it can be challenging to publish or consume data at a rate that keeps up with real-time. Optimizing the speed of your producers or consumers involves knowing what specific values to use for a variety of performance related variables:
- How many worker threads should my producers (or consumers) have?
- How many topics should my producers send to?
- How many partitions should my topics have?
- Should I enable compression? If so, should I use the gzip, snappy, or lz4 codec?
- How long should my producers wait to allow other records to be sent so that the sends can be batched together?
- How large should I make those batches?
- What’s the smallest virtual machine configuration that I can use to achieve my real-time throughput requirements?
(By the way, from my experience I found that the first three factors are the most significant - number of threads per producer, number of topics they send to, and the number of partitions in each topic. I didn’t spend much time optimizing the parameters for batching, but my instinct tells me they don’t matter as much).
One method of tuning these parameters is to just run a series of incremental unit tests designed to measure throughput over a range of values for a single parameter. JUnit provides an excellent means of performing parameterized unit tests.
What is JUnit?
JUnit is a unit testing framework for the Java programming language and is by far the most popular framework for developing test cases in Java.
I recently developed some JUnit tests to find which Kafka configurations would maximize the speed at which I could publish messages into a Kafka stream. In fact, these unit tests don’t so much test anything as produce speed data so that different configurations of Kafka producers can be adjusted to get optimal performance under different conditions.
The following is one example of a unit test I used to parameterize threads and topics. I found this test extremely helpful in understanding how many threads I should allocate to my producers. It was also very revealing to see at what point Kafka (in its default out-of-the-box configuration) could not handle any more topics.
Note, this code and documentation for compiling and running it is contained in the following GitHub repository: https://github.com/mapr-demos/finserv-application-blueprint
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
import com.google.common.collect.Lists;
import com.google.common.io.Resources;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.junit.runners.Parameterized;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.*;
import java.util.concurrent.*;
/**
* PURPOSE:
* Test the effect of threading on message transmission to lots of topics
*/
@RunWith(Parameterized.class)
public class ThreadCountSpeedTest {
private static final double TIMEOUT = 30; // seconds
private static final int BATCH_SIZE = 1000000; // The unit of measure for throughput is "batch size" per second
// e.g. Throughput = X "millions of messages" per sec
@BeforeClass
public static void openDataFile() throws FileNotFoundException {
data = new PrintWriter(new File("thread-count.csv"));
data.printf("threadCount, topicCount, i, t, rate, dt, batchRate\n");
}
@AfterClass
public static void closeDataFile() {
data.close();
}
private static PrintWriter data;
@Parameterized.Parameters(name = "{index}: threads={0}, topics={1}")
public static Iterable<Object[]> data() {
return Arrays.asList(new Object[][]{
{1, 50}, {2, 50}, {5, 50}, {10, 50},
{1, 100}, {2, 100}, {5, 100}, {10, 100},
{1, 200}, {2, 200}, {5, 200}, {10, 200},
{1, 500}, {2, 500}, {5, 500}, {10, 500},
{1, 1000}, {2, 1000}, {5, 1000}, {10, 1000},
{1, 2000}, {2, 2000}, {5, 2000}, {10, 2000}
});
}
private int threadCount; // number of concurrent Kafka producers to run
private int topicCount; // number of Kafka topics in our stream
private int messageSize = 100; // size of each message sent into Kafka
private static final ProducerRecord<String, byte[]> end = new ProducerRecord<>("end", null);
public ThreadCountSpeedTest(int threadCount, int topicCount) {
this.threadCount = threadCount;
this.topicCount = topicCount;
}
private static class Sender extends Thread {
private final KafkaProducer<String, byte[]> producer;
private final BlockingQueue<ProducerRecord<String, byte[]>> queue;
private Sender(KafkaProducer<String, byte[]> producer, BlockingQueue<ProducerRecord<String, byte[]>> queue) {
this.producer = producer;
this.queue = queue;
}
@Override
public void run() {
try {
ProducerRecord<String, byte[]> rec = queue.take();
while (rec != end) {
// Here's were the sender thread sends a message.
// Since we're not supplying a callback the send will be done asynchronously.
// The outgoing message will go to a local buffer which is not necessarily FIFO,
// but sending messages out-of-order does not matter since we're just trying to
// test throughput in this class.
producer.send(rec);
rec = queue.take();
}
} catch (InterruptedException e) {
System.out.printf("%s: Interrupted\n", this.getName());
}
}
}
@Test
public void testThreads() throws Exception {
System.out.printf("threadCount = %d, topicCount = %d\n", threadCount, topicCount);
// Create new topic names. Kafka will automatically create these topics if they don't already exist.
List<String> ourTopics = Lists.newArrayList();
for (int i = 0; i < topicCount; i++) {
// Topic names will look like, "t-00874"
ourTopics.add(String.format("t-%05d", i));
}
// Create a message containing random bytes. We'll send this message over and over again
// in our performance test, below.
Random rand = new Random();
byte[] buf = new byte[messageSize];
rand.nextBytes(buf);
Tick message = new Tick(buf);
// Create a pool of sender threads.
ExecutorService pool = Executors.newFixedThreadPool(threadCount);
// We need some way to give each sender messages to publish.
// We'll do that via this list of queues.
List<BlockingQueue<ProducerRecord<String, byte[]>>> queues = Lists.newArrayList();
for (int i = 0; i < threadCount; i++) {
// We use BlockingQueue to buffer messages for each sender.
// We use this type not for concurrency reasons (although it is thread safe) but
// rather because it provides an efficient way for senders to take messages if
// they're available and for us to generate those messages (see below).
BlockingQueue<ProducerRecord<String, byte[]>> q = new ArrayBlockingQueue<>(1000);
queues.add(q);
// spawn each thread with a reference to "q", which we'll add messages to later.
pool.submit(new Sender(getProducer(), q));
}
double t0 = System.nanoTime() * 1e-9;
double batchStart = 0;
// -------- Generate Messages for each Sender --------
// Generate BATCH_SIZE messages at a time and send each one to a random sender thread.
// The batch size was defined above as containing 1 million messages.
// We want to send as many messages as possible until a timeout has been reached.
// The timeout was defined above as 30 seconds.
// We'll break out of this loop when that timeout occurs.
for (int i = 0; i >= 0 && i < Integer.MAX_VALUE; ) {
// Send each message in our batch (of 1 million messages) to a random topic.
for (int j = 0; j < BATCH_SIZE; j++) {
// Get a random topic (but always assign it to the same sender thread)
String topic = ourTopics.get(rand.nextInt(topicCount));
// The topic hashcode works in the sense that equal topics always have equal hashes.
// So this will ensure that a topic will always be populated by the same sender thread.
// We want to load balance senders without using round robin, because with round robin
// all senders would have to send to all topics, and we've found that it's much faster
// to minimize the number of topics each kafka producer sends to.
// By using this hashcode we can maintain affinity between Kafka topic and sender thread.
int qid = topic.hashCode() % threadCount;
if (qid < 0) {
qid += threadCount;
}
try {
// Put a message to be published in the queue belonging to the sender we just selected.
// That sender will automatically send this message as soon as possible.
queues.get(qid).put(new ProducerRecord<>(topic, message.getData()));
} catch (Exception e) {
// BlockingQueue might throw an IllegalStateException if the queue fills up.
e.printStackTrace();
}
}
i += BATCH_SIZE;
double t = System.nanoTime() * 1e-9 - t0;
double dt = t - batchStart;
batchStart = t;
// i = number of batches (number of "1 million messages" sent)
// t = total elapsed time
// i/t = throughput (number of batches sent overall per second)
// dt = elapsed time for this batch
// batch / dt = millions of messages sent per second for this batch
data.printf("%d,%d,%d,%.3f,%.1f,%.3f,%.1f\n", threadCount, topicCount, i, t, i / t, dt, BATCH_SIZE / dt);
if (t > TIMEOUT) {
break;
}
}
// We cleanly shutdown each producer thread by sending the predefined "end" message
// then shutdown the threads in the pool after giving them a few seconds to see that
// end message.
for (int i = 0; i < threadCount; i++) {
queues.get(i).add(end);
}
pool.shutdown();
pool.awaitTermination(10, TimeUnit.SECONDS);
}
KafkaProducer<String, byte[]> getProducer() throws IOException {
Properties props = new Properties();
props.load(Resources.getResource("producer.props").openStream());
// Properties reference:
// https://kafka.apache.org/090/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html
// props.put("batch.size", 16384);
// props.put("linger.ms", 1);
// props.put("buffer.memory", 33554432);
return new KafkaProducer<>(props);
}
}
Here is what my maven dependency for JUnit looks like in pom.xml:
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>Here’s how I run that test:
mvn -e -Dtest=ThreadCountSpeedTest testWhen the test completes, it generates a data file called thread-count.csv. The following R script will process that data file and generate an image like the one shown below.
png(file="thread.png", width=800, height=500, pointsize=16)
x = read.csv("thread-count.csv")
boxplot(batchRate/1e6 ~ topicCount + threadCount, x, ylim=c(0,2.1),
ylab="Millions of messages / second", xlab="Topics",
col=rainbow(4)[ceiling((1:30)/6)], xaxt='n')
axis(1,labels=as.character(rep(c(50,100,200,500,1000,2000),4)), at=(1:24), las=3)
legend(x=21,y=2.1,legend=c(1,2,5,10), col=rainbow(4), fill=rainbow(4), title="Threads")
abline(v=6.5, col='lightgray')
abline(v=12.5, col='lightgray')
abline(v=18.5, col='lightgray')
dev.off()Once you download thread-count.csv to your working directory, you can run that R script with Rscript draw-speed-graphs.r, which should generate an image file “thread.png” that should look something like this:
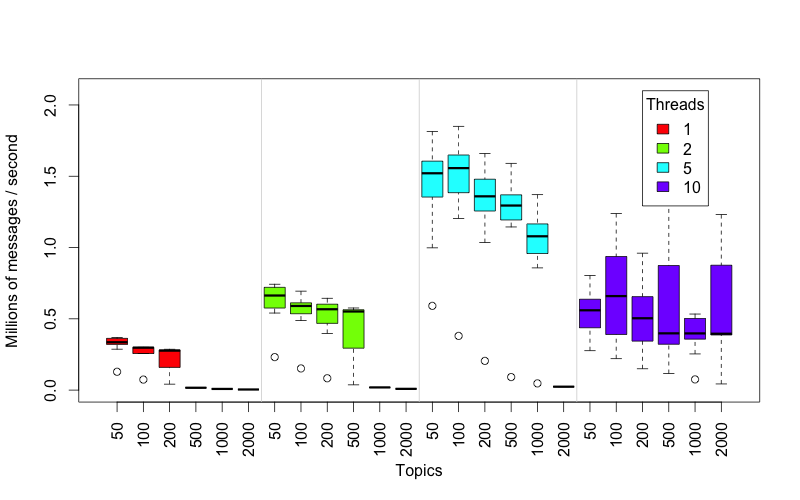
Fewer topics is better.
In the image shown above, I observed that the more topics a Kafka producer has to send to the slower it will run. In other words, it’s faster to send 1000 messages to a single topic that to send 500 messages to 2 topics in the same Kafka broker. In my specific test environment, it seemed apparent that performance would significantly degrade if any of my producer threads were sending to more than 200 topics. Therefore, it is important to maintain an affinity between producer thread and Kafka topics, such that any given topic will always be populated by the same producer thread.
Disclaimer: I didn’t really question the result which showed my producers failing beyond 200 topics per producer thread. I just tried to limit my producers to fewer than 200 topics.
In case you’re curious, I got that result on a single-node Kafka cluster (kafka_2.11-0.10.0.0) running on Ubuntu Linux (canonical:UbuntuServer:14.04.4-LTS) on a DS14-series server in Azure (the Standard DS14 has 16 cores and 112 GB memory).
Conclusion
The three primary factors I found most important in producing messages as fast as possible to Kafka are:
- Number of concurrent Producers
- Number of Kafka topics
- Number of partitions per Kafka topic
JUnit’s capacity for running parameterized tests is an excellent way to generate quantitative results that can be used to optimize the throughput of your Kafka stream analytics.
The most important finding in our study was that it is very important to maintain an affinity between producer threads and Kafka topics, such that any given topic will always be populated by the same producer thread. Knowing exactly how many topics can be handled by a producer thread will vary from system to system, but in our case we found optimal performance when no more than 200 topics were handled by each producer thread.
The code in this post is contained in the following GitHub repository: https://github.com/mapr-demos/finserv-application-blueprint
